Zweiter Arbeitsbericht aus der Erfolgsgeschichte „Integrierte Datenanalyse zur Kollaboration in der Auftragsplanung“ von ERCO (UC3)
Ziel des dritten Use Cases ist die Implementierung einer prädiktiven Analyse zur optimalen Ressourcenallokation und Kollaboration der Geschäftsbereiche des Unternehmens. Zudem sollen neue Kompetenzen aufgebaut werden und die Entwicklung der Organisation zu einem höheren Reifegrad in Data Science Projekten vorangetrieben werden.
Einführung in den Use Case von ERCO
Als Anwendungspartner bringt ERCO im Rahmen eines mittelständischen Unternehmens, die Kompetenzen in der Ausbildung, Weiterentwicklung und Qualifizierung von Mitarbeitern in das Projekt AKKORD ein. Außerdem verfügt ERCO bereits über eine Datenbasis mit einem hohen Vernetzungsgrad und die grundsätzliche Fähigkeit analytische Vorgehensweisen in der Steuerung der Supply Chain einzusetzen (Abbildung 1). ERCO möchte die Informationen aus Angeboten und Aufträgen des ERP-Systems (SAP R/3) mit Informationen aus dem Customer Relationship Management System (SAP CRM) anreichern und eine auf Algorithmen basierende Prognose etablieren. Diese Vorhersage wird zudem mit Daten aus Social Media Quellen bzw. der „erco.com“ Webseite ergänzt. Die Daten dienen somit als Grundlage der Planung von Unternehmensressourcen. Im Rahmen der unternehmensweiten Kollaboration der Vertriebsgesellschaften sowie der Fertigung und der Produktion bis hin zur Lieferantenintegration, geht die Prognose steuernd in das ERCO Wertschöpfungssystem ein. Hier steht die Nutzung der KI-Software RapidMiner im Vordergrund.
Abbildung 1: Vorgehensweise Use-Case 3
Vorgehensweise zur integrierten Auftragsprognose auf Basis von Marktinformationen
Die Auftragsprognose bei ERCO basiert auf zwei Säulen von Datenstrukturen in einem SAP-System. Es sind zum einen die Projektinformationen der sogenannten Opportunity aus dem Customer Relationship Management System und zum anderen die Angebotsdaten aus dem ERP-System.
Die Opportunity (das ERCO Projekt) ist mit dem Meilenstein des „voraussichtlichen Auftragseingangsdatums“ erfasst. Dieses Datum kann sich über den Projektzeitraum ändern und wird regelmäßig angepasst. In Verbindung mit den, zum Projekt verknüpften SAP-ERP-Angebotsdaten (Produkt + Menge), wird ein voraussichtlicher Bedarf für die Zeitspanne von vier Monaten ermittelt.
Die Vorhersage des voraussichtlichen Auftragseingangs wird für die kapazitive Auslegung der ERCO Produktion im Demand Planning und zur Justierung der Lieferkette bei erkennbaren Veränderungen der Nachfrage genutzt. Die verantwortliche und koordinierende Stelle ist das Projekt- und Auftragszentrum. Die Steuerung der Supply Chain erfolgt in der Zusammenarbeit mit dem externen Lieferanten, dem Einkauf, der Fertigung und Montage sowie den Regionalen Verkaufsorganisationen, weltweit.
Arbeitsstand in der integrierten Datenanalyse
Als Grundlage für die Prognose wird der Cross-Industry Standard Process for Data Mining (CRISP-DM, Abbildung 2) angewandt.
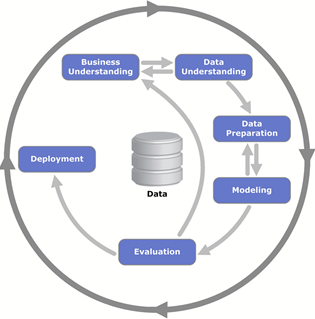
Abbildung 2: Cross Industry Standard Process for Data Mining
Bei der Anwendung dieses Standards, steht zu Beginn die Definition des Geschäftsprozesses und die Entwicklung einer Zielvorgabe im Vordergrund. Die Zielvorgabe sollte berücksichtigen, dass es für Data Science Projekte keine immanente Garantie für die Erreichung des definierten Zieles geben kann. Die Zielvorgabe in dem Use Case wurde mit einer Prognosegenauigkeit von + / – 20 % zum real eingetretenen Auftragseingangswert in Stück definiert. Das Unternehmen ERCO hat grundsätzlich das Ziel eine solche Nachfrageschwankung über kapazitive und dispositive Reserven abfangen zu können.
In der folgenden Projektarbeit wurde der Schwerpunkt zunächst auf die drei vorbereitenden Elemente des CRISP-DM gelegt:
1. Data Understanding
2. Data Preparation
3. Modeling
Bei diesen drei aufeinander folgenden Phasen steht die Bereinigung der Daten, sowie die Vorverarbeitung und der Aufbau einer Datenstruktur und gegebenenfalls Übersetzungstabellen im Vordergrund. An dieser Stelle entstehen Module wie die Umrechnung von Einheiten (z.B. Währungen oder Datumsextraktionen). Die hier investierte Zeit verkürzt nachfolgende Phasen der Modellanwendung und Validierung.
In der derzeitigen Forschungsprojektphase wird intensiv und regelmäßig an der Evaluation der Prognoseergebnisse mit dem Abgleich auf die Projektziele gearbeitet. Die Erfahrung hat gezeigt, dass es regelmäßig relevant ist, Ergebnisse der Prognose mit Bezug auf den Geschäftsprozess zu interpretieren.
Nutzung der Zeitreihenanalyse als Vorhersagemodell
Die Vorhersage des Auftragseinganges in Stück und Wert zu einem in der Zukunft liegenden Datum (Woche / Monat) wird unter Anwendung der Zeitreihenanalyse vorgenommen (Abbildung 3). Die Grundlage ist eine vorgegebene feste Reihenfolge von Daten und die Betrachtung der Vorhersage als Supervised-Learning-Modell. In diesem Modell wird für eine definierte Menge von Eingabedaten der Wert einer Ausgabevariable / Zielvariable (Label) vorhergesagt. Grundlage für das Machine Learning sind hier die historische Eingabedaten des vier-Monats-Fensters und die historischen Ausgabedaten (Realer Auftragseingang im Zeitraum des vergangenem vier-Monats-Fensters).
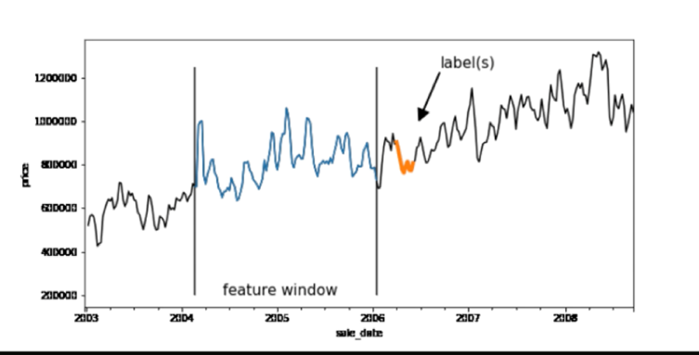
Abbildung 3: Zeitreihenanalyse
Der blau dargestellte Teil des Graphs beschreibt die Größe der Zeitreihe für das Training des Modells. Der orange dargestellte Bereich der Zeitachse umfasst die Größe des Vorhersagezeitraums. Zur Verifizierung des Vorhersagewertes wurden drei Zeitreihen-Algorithmen in RapidMiner Studio angewandt (Abbildung 5):
-Arima
-Holt-Winters
-Seasonal
Bei der Verifizierung zeigte der Algorithmus „Holt-Winters“ die geringste Abweichung vom vorgegebenen Ziel von +-/ 20 % des eingetroffenen Auftragseingangs in Menge und Wert (Abbildung 4).
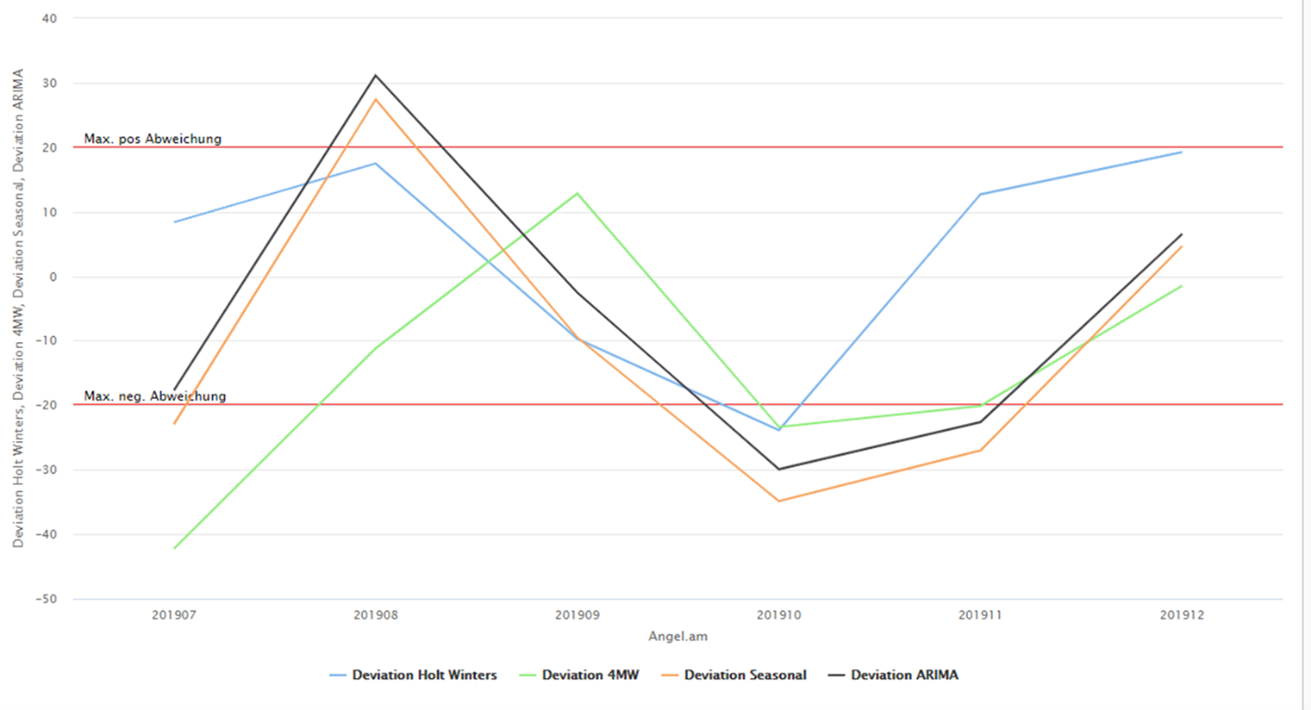
Abbildung 4: Grafische Auswertung der Vorhersagemodelle
Der blaue Graph beschreibt die maximale und minimale Abweichung vom Ist-Auftragseingang des „Holt-Winters“-Algorithmus. Somit wurde dieser Algorithmus für die weitere Optimierung/Validierung herangezogen.
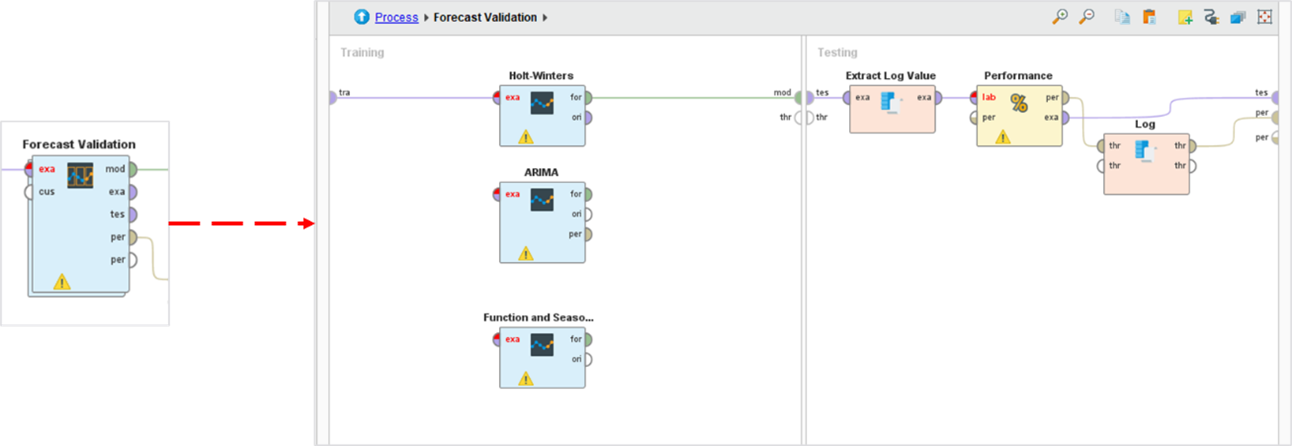
Abbildung 5: Prozesskette der Vorhersagemodelle in RapidMiner Studio
In der weiteren Validierung konnte keine Verbesserung der Ergebnisse auch nach der Anreicherung der Daten durch Informationen aus dem ERCO CRM erreicht werden. Aus diesem Grund wird nun die Anwendung eines Entscheidungs-Baum Modells (Decision Tree) vorangetrieben und in der Folgezeit des Projektes erprobt.
Anwendung der Entscheidungsbaumanalyse als Vorhersagemodell
Erste Ergebnisse werden auf der Grundlage einer sogenannten Konfusionsmatrix (Abbildung 6) dargestellt. Das Ziel ist hier in iterativen Schritten die Bewertungsindikatoren innerhalb der Matrix zu verbessern und somit die Aussagekraft der Analyse zu stärken:

Abbildung 6: Konfusionsmatrix
Die aus der Matrix resultierenden Indikatoren sind:
Recall (Verhältnis der richtig klassifizierten erhaltenen Aufträge zu allen korrekt vorhergesagten Aufträgen) auch Sensitivitätsrate genannt, TP / (TP + FN)
Precision (Rate der richtigerweise positiv klassifizierten Werte, beschreibt die Relevanz und Genauigkeit,) TP / (TP + FP)
Accuracy (Prozentual richtig klassifizierte Werte) richtig klassifizierte / alle Klassifizierungen. Es wird die Genauigkeit in Bezug auf die vorher definierte Zielvariable (Label) beschrieben.
Die nachfolgende Abbildung 7 soll den Zusammenhang der „Precision“ zu der „Accuracy“ darstellen:
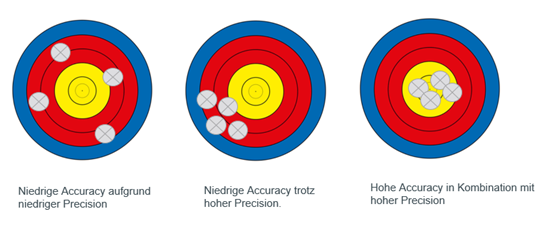
Abbildung 7: Grafische Darstellung von Precision und Accuracy
Die bisher erreichten Indikatorwerte im Use Case sind in Abbildung 8 dargestellt:

Abbildung 8: Indikatorwerte des Use Cases in der Konfusionsmatrix
Der Recall liegt bei 62 %, die Präzision der richtigerweise positive vorhergesagten Auftragseingänge liegt bei 71 % und die Genauigkeit liegt bei knapp 77 %.
Die derzeitige Genauigkeit entspricht einem Wert, der schon besser als die sogenannte Domänenerfahrung (Bauchgefühl) ist und es gibt durchaus Empfehlungen die Analyse auf diesem Niveau zum Ausrollen (Deployment) zu bringen.
Nächste Schritte
Die nächsten Schritte bestehen nun aus der regelmäßigen Anwendung und Auswertung bestehender und aktueller Daten auf die erstellten Prognosemodule und Machine Learning Modelle im Rapid Miner Studio. Im Weiteren wird die Planung und Durchführung des letzten wichtigen Schritts, des „Deployments“ im CRISP-DM Modell, umgesetzt.
Autor und Ansprechpartner: