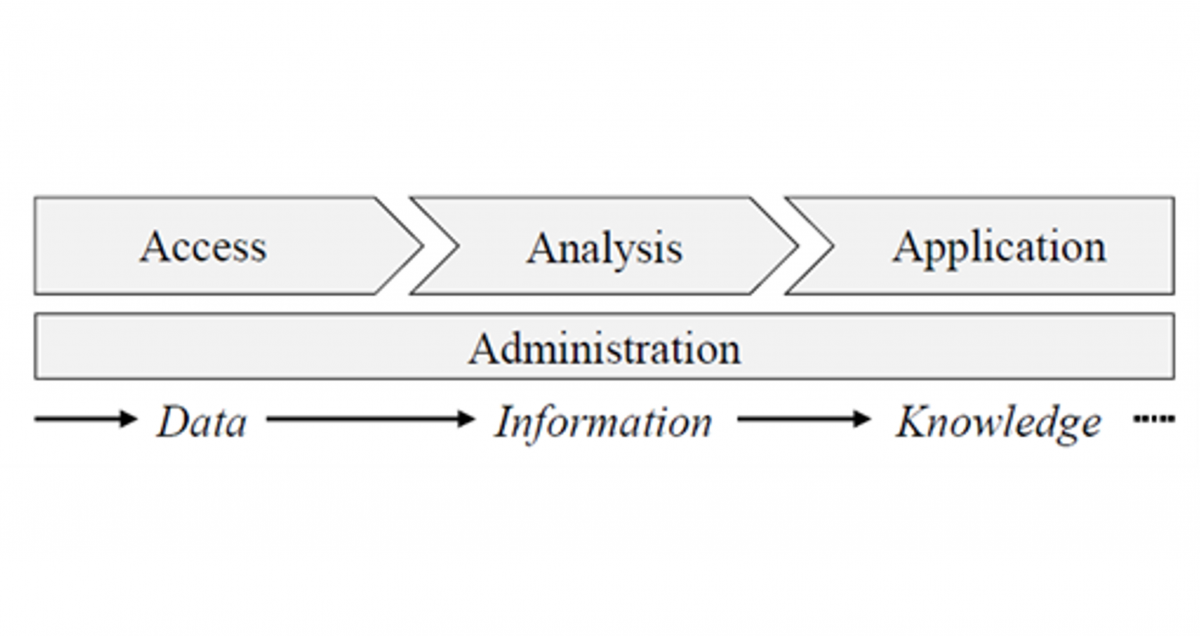
3rd work report from the research area “Data Backend System”
In the research area “Data Backend System”, modules for uniform data access are developed. These are used in the project to provide data to subsequent analysis processes. The work is based on the requirements identified in the project and is validated with the application partners using the AKKORD use cases.
Implementation
After the first two work reports focused on the conceptual approaches pursued in the research area, this report will primarily describe the implementation of the technical solutions. Specifically, three different approaches to the integration of data are presented, which, depending on the intended deployment scenario, can form the backend of a data analytics platform either individually or in combination.
Data integration approach 1: Data warehouse
In the classic data warehouse approach, different data sources are integrated in a staging database (“master data”). These data can be of different nature in their respective original state, e.g. structured databases, raw sensor data, or further unstructured data. In particular, this includes data provided from a centralized data backend (see Approach 3) or a decentralized solution (Approach 2, see Figure 1).
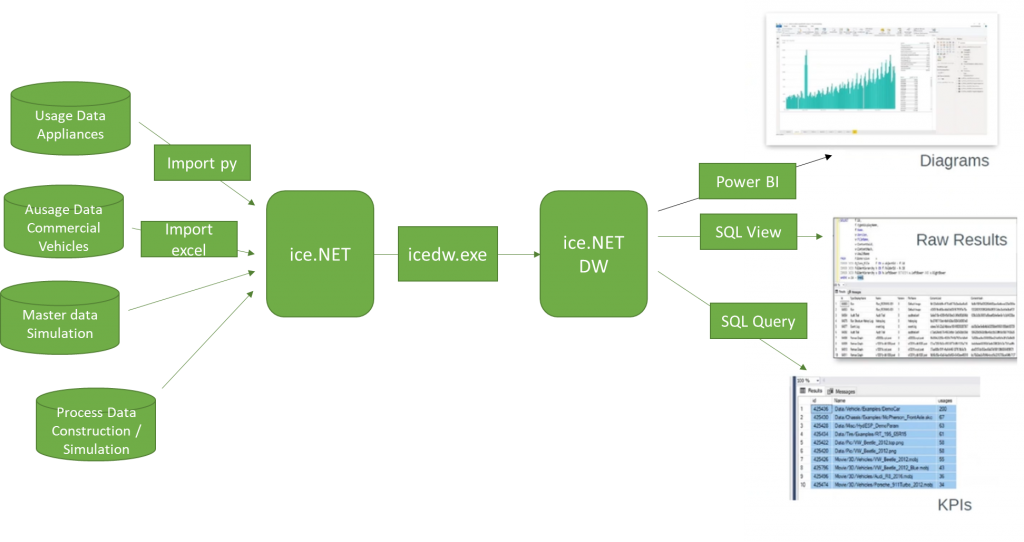
Figure 1 Data warehouse approach
In the staging database, the data is then normalized by the data warehouse builder and, if necessary, pre-processed/transformed in other ways so that it can be made available in a suitable form to the reporting, data mining or analysis processes envisaged in each case. In the research project, solutions based on ice.NET of the company PDTec were used. Figure 1 shows the practical implementation of approach 1 in the context of the reference building block developed in the project.
Data integration approach 2: Decentralized linking using metadata
In this data integration approach, the data remains in their respective source systems, and deep copies of the data are not created initially. Instead, only the information “data set A exists in source system B” and “data set A is related to data set C” is stored (Figure 2). Combining a lot of this information sets results in a graph that can be enriched with additional information, for example, to model cross-system cross-relationships between data sets. If a complete data set is needed, it can be queried in the original system.
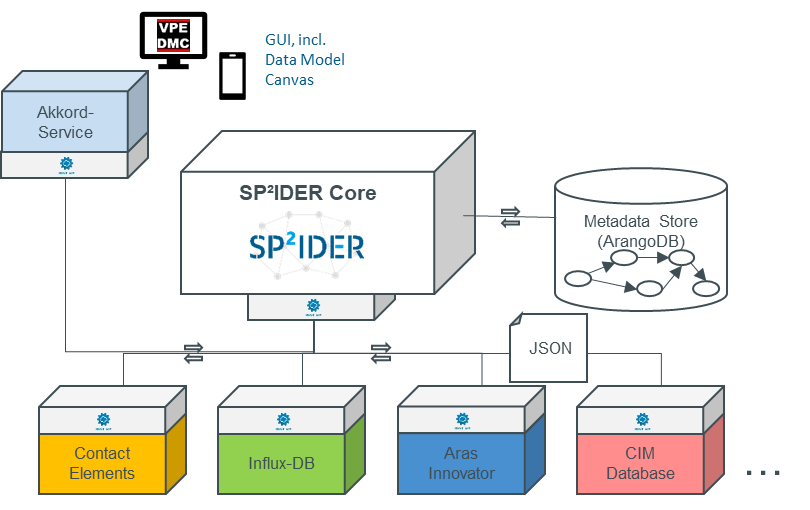
Figure 2 decentralized data linking
In the AKKORD research project, the SP²IDER system developed at the VPE chair is used for decentralized integration. The system has already been described in various publications, including the article “Supporting semantic PLM by using a lightweight engineering metadata mapping engine”.
Data integration approach 3: Building a central data model
In this approach, all data is stored in a central platform. The data model can encompass a wide variety of data sources and map detailed links. The database used can already provide tools for further networking, processing or evaluating the data. In the context of product data or data from the IoT (Internet of Things), it makes sense to choose an appropriate platform, such as a PLM (Product-Lifecycle-Management) software solution for managing product lifecycle data.
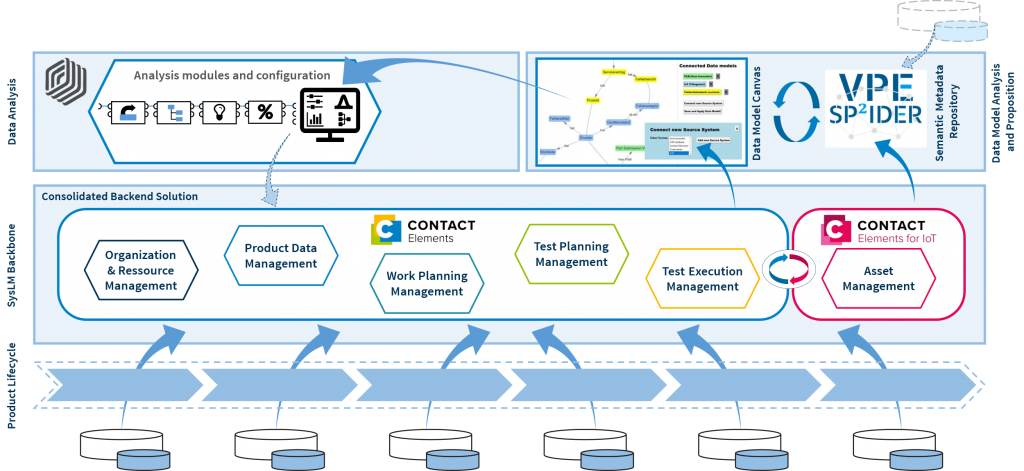
Figure 3 Centralized data model
In the research project, a central data model was created in the Elements’ platform of the producer Contact Software. An excerpt from the data model is shown in Figure 3. Further details on the approach can be found in the publication “Data Networking for Industrial Data Analysis Based on a Data Backbone System”, among others. This also describes how a central backend can be combined with the SP²IDER system from approach 2 in order to combine targeted data for an analysis and pass it on to the analysis modules developed in the project.
Selection and combination of approaches
The strength of the data warehouse approach lies in the flexible pre-processing in the staging database, as here an unrestricted transformation of the data can be performed. As described earlier, the other two approaches can be incorporated by transferring the data to the staging database through a suitable interchange format.
The decentralized approach does not require the introduction of a large new database. Via open standards, new source systems can be accessed with relatively little effort, which is why the approach was often used as a “data provider” for the other two approaches in the context of the research project.
The development of a central data model makes sense if a high level of integration and direct access to data from live operations are required in the envisaged deployment scenario. If a complete back-end solution is to be built without pre-existing databases, a central back-end directly provides a place where data can be persistently stored. Here, too, combinations with the decentralized approach make sense, as shown in the description of approach 2.
Author and Contact Person: