Dritter Arbeitsbericht aus dem Leistungsbereich „Daten-Backend-System“
Im Leistungsbereich „Daten-Backend-System“ werden Bausteine für einen einheitlichen Zugriff auf Daten entwickelt. Diese werden im Projekt für den Datenzugriff zwecks anschließender Analyse eingesetzt. Die Arbeiten orientieren sich dabei an den im Projekt ermittelten Anforderungen und werden anhand der AKKORD Use Cases mit den Anwendungspartnern validiert.
Implementierung
Nachdem in den ersten beiden Arbeitsberichten die im Leistungsbereich verfolgten konzeptuellen Ansätze im Vordergrund standen, soll es in diesem Bericht vorrangig um die Implementierung der technischen Lösungen gehen. Konkret werden drei unterschiedliche Ansätze zur Integration von Daten vorgestellt, die je nach angestrebtem Einsatzszenario einzeln oder in Kombination das Backend einer Datenanalyse-Plattform bilden können.
Datenintegrationsansatz 1: Data Warehouse
Im klassischen Data Warehouse-Ansatz werden verschiedene Datenquellen in einer Staging-Datenbank („Master Data“) integriert. Diese Daten können in ihrem jeweiligen Ursprungszustand unterschiedlicher Natur sein, z.B. strukturierte Datenbanken, Sensor-Rohdaten oder weitere unstrukturierte Daten. Dies schließt insbesondere auch Daten mit ein, die aus einem zentralen Daten-Backend (siehe Ansatz 3) oder einer dezentralen Lösung (Ansatz 2) zur Verfügung gestellt werden (Abbildung 1).
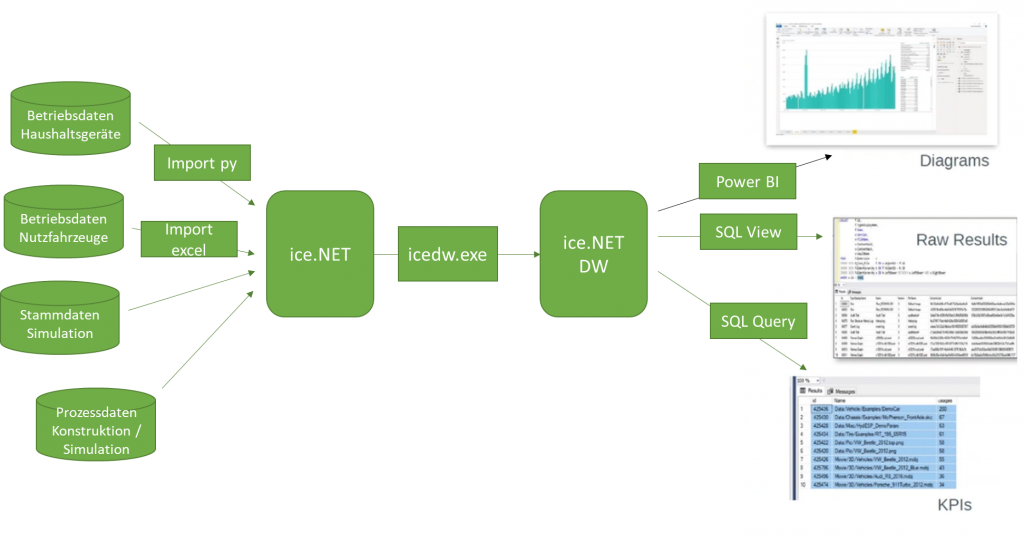
Abbildung 1 Data Warehouse-Ansatz
In der Staging-Datenbank werden die Daten anschließend durch den Data Warehouse Builder normalisiert sowie ggf. auf weitere Arten vorbearbeitet/transformiert, um in geeigneter Form den jeweils angedachten Reporting-, Data Mining- oder Analyse-Prozessen zur Verfügung gestellt werden können. Im Forschungsprojekt kamen konkret Lösungen auf Basis von ice.NET der Firma PDTec zum Einsatz. In Abbildung 1 ist die praktische Umsetzung von Ansatz 1 im Kontext des im Projekt entwickelten Referenzbaukastens dargestellt.
Datenintegrationsansatz 2: Dezentrale Verlinkung mithilfe von Metadaten
In diesem Datenintegrationsansatz verbleiben die Daten in ihren jeweiligen Quellsystemen, tiefe Kopien der Daten müssen zunächst nicht erstellt werden. Stattdessen werden nur die Informationen „Datensatz A existiert in Quellsystem B“ und „Datensatz A steht in Beziehung zu Datensatz C“ gespeichert (vgl. Abbildung 2). Aus vielen solchen Beziehungen entsteht ein Graph, der mit zusätzlichen Informationen angereichert werden kann, um beispielsweise systemübergreifende Querbeziehungen zwischen Datensätzen zu modellieren. Wird ein kompletter Datensatz benötigt, kann dieser im ursprünglichen System abgefragt werden.
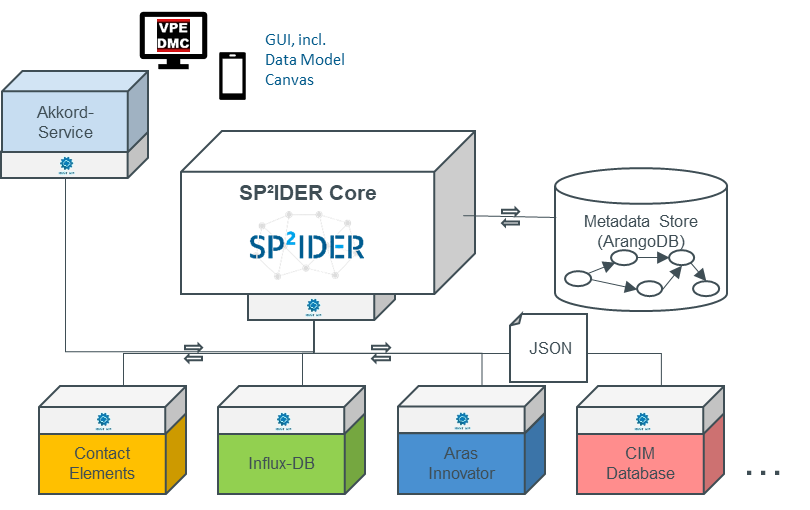
Abbildung 2 Dezentrale Datenverlinkung
Im Forschungsprojekt AKKORD kommt für die dezentrale Integration das am Lehrstuhl VPE entwickelte SP²IDER-System zum Einsatz. Das System wurde bereits in verschiedenen Publikationen beschrieben, u.a. in dem Artikel „Supporting semantic PLM by using a lightweight engineering metadata mapping engine“.
Datenintegrationsansatz 3: Aufbau eines zentralen Datenmodells
In diesem Ansatz werden alle Daten in einer zentralen Plattform gespeichert. Das Datenmodell kann hierbei unterschiedlichste Datenquellen umfassen und detaillierte Verknüpfungen abbilden. Die eingesetzte Datenbank kann bereits Werkzeuge zur weiteren Vernetzung, Bearbeitung oder Auswertung der Daten mitliefern. Im Kontext von Produktdaten oder Daten aus dem IoT (deutsch: Internet der Dinge) ist es sinnvoll, eine angemessene Plattform zu wählen, wie beispielsweise eine PLM-Softwarelösung (Product-Lifecycle-Management) für die Verwaltung von Produktlebenszyklusdaten.
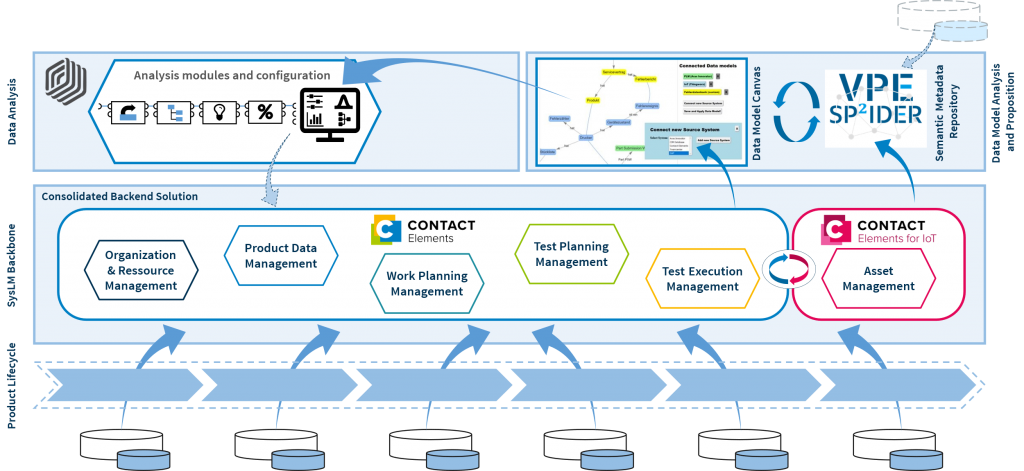
Abbildung 3 Zentrales Datenmodell
Im Forschungsprojekt wurde ein zentrales Datenmodell in der Elements-Plattform des Herstellers Contact Software erstellt. Ein Auszug aus dem Datenmodell ist in Abbildung 3 dargestellt. Weitere Details zum Ansatz sind unter anderem in der Veröffentlichung „Data Networking for Industrial Data Analysis Based on a Data Backbone System“ zu finden. Hier ist auch beschrieben, wie ein zentrales Backend mit dem SP²IDER-System aus Ansatz 2 kombiniert werden kann, um gezielt Daten für eine Analyse zusammenzuführen und an die im Projekt entwickelten Analysebausteine weiterzugeben.
Auswahl und Kombination der Ansätze
Die Stärke des Data Warehouse-Ansatzes liegt in der flexiblen Vorverarbeitung in der Staging Datenbank, da hier eine uneingeschränkte Transformation der Daten vorgenommen werden kann. Wie bereits beschrieben können die anderen beiden Ansätze eingebunden werden, indem die Daten durch ein geeignetes Austauschformat in die Staging-Datenbank übertragen werden.
Der dezentrale Ansatz kommt ohne die Einführung einer großen neuen Datenbank aus. Über offene Standards kann mit relativ geringem Aufwand auf neue Quellsysteme zugegriffen werden, weshalb der Ansatz im Kontext des Forschungsprojektes auch oft als „Datenlieferant“ für die beiden anderen Ansätze zum Einsatz kam.
Der Aufbau eines zentralen Datenmodells ist sinnvoll, wenn im angedachten Einsatzszenario eine hohe Integrationstiefe und ein direkter Zugriff auf Daten aus dem Live-Betrieb erforderlich sind. Sofern eine vollständige Backend-Lösung ohne zuvor bestehende Datenbanken aufgebaut werden soll, liefert ein zentrales Backend direkt einen Ort, an dem Daten persistent gespeichert werden können. Auch hier sind Kombinationen mit dem dezentralen Ansatz sinnvoll, wie in der Beschreibung von Ansatz 2 aufgezeigt wird.
Autor und Ansprechpartner: