Work report from the research area “Data-Backend-System” – Data access
In the research area “Data-Backend-System”, modules for uniform access to data are developed. These are used in the project for data access for the purpose of subsequent analysis. The work is based on the requirements determined in the project and is validated with the application partners on the basis of the AKKORD use cases.
State of the Art
A fundamental prerequisite for performing industrial data analyses is the availability of data. In order to gain new insights and knowledge from analyses, data from several systems distributed across the company is often required. However, the data must not just be accessible for analysis, but also prepared in a suitable manner. The requirements for access as well as transformation or preparation depend heavily on a wide variety of factors. A central aspect, especially from the perspective of the data backend system, is the IT system landscape present in the company. Other relevant factors result from the intended analysis goal, the planned analysis method, and its intended technical implementation.
Goals and methodology
The objective of work package 6 is the development of a modular data backend concept, which allows the development of an individual implementation depending on the given constraints for a specific customer. The data backend system is closely linked to the data analysis modules and provides them with a uniform interface, which helps to standardize data access and thus simplify analysis processes. The structure of the backend system in a company can vary greatly depending on the existing IT system landscape as well as the intended goal. Ideally, a comprehensive solution is pursued, which bundles all relevant data of the company and subsequently only needs to be maintained with little effort. This frontloading in the analysis process ensures that future analysis projects can be realized with significantly reduced overall effort.

Figure 1: Backend system in context of industrial data analysis
Within the scope of the research areas, different scenarios that can be used in a modular fashion are pursued in order to enable analysis. The starting point for the introduction of a data backend system is a survey of the current situation. This involves mapping the data kept in the company within a model and noting in which system the data is persisted.
This step is supported by a building block of the reference toolkit, the Data Model Canvas. The Data Model Canvas provides a lightweight and flexible tool for analyzing and linking data models. Here, data models for different data sources are linked together in a graph-based user interface. This provides information about which required data can be found where and which relationships exist between data from different sources. From the user’s point of view, the focus is on an intuitive user interface and the possibility of importing existing preliminary considerations (e.g., in the form of UML diagrams). In the case of very extensive system landscapes, logically related sub-areas are identified and initially considered separately in order to ensure manageability. If necessary, the defined subareas can then be linked. Once the data model has been created, it is compared with the goals and requirements of the analysis. This reveals any deficits in the data inventory at an early stage and opens up the possibility for measures such as adapting the analysis or collecting additional data. Once the model meets the needs of the analysis, it can be used as the basis for building the backend. The reference toolkit includes different approaches that are compatible with each other and are intended to support different IT strategies in companies.
Placement in the project context
The figures in this report show the building blocks developed in the project for the backend (once in the larger context with the associated data analysis and presentation of the results and once focused on data access).

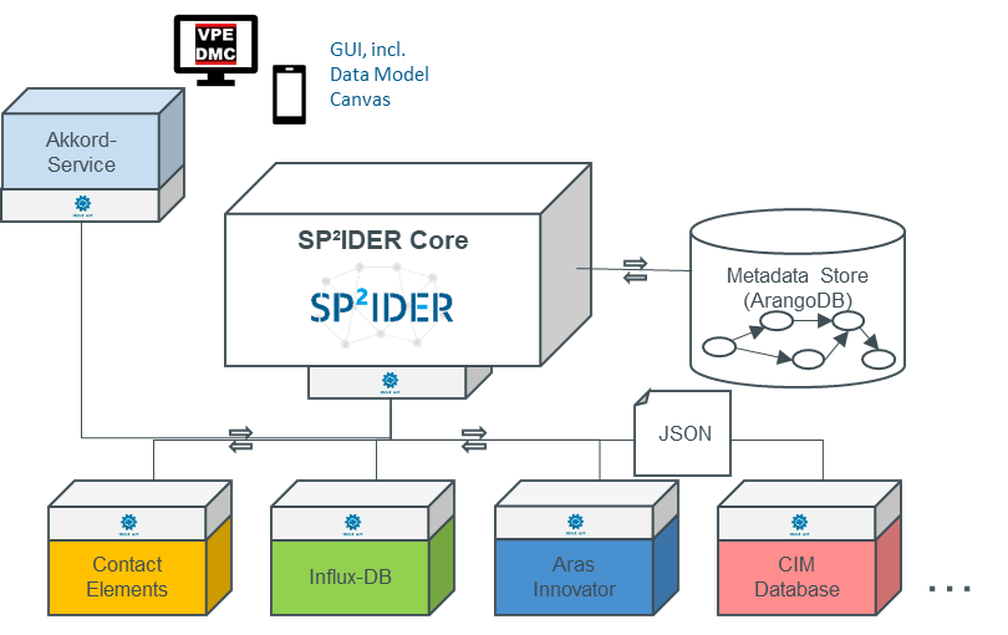
Figure 2: Data access modules
Overall, the resulting toolbox also provides a flexible, modular solution that can be adapted to the requirements of the respective company. Thus, in addition to the presented process and tool for analyzing existing data models, solutions are available for setting up a staging database for analyses in a controlled environment (project partner: PdTec), concepts for decentralized access to data by means of managing a common metadata model (project partner: VPE), and scalable concepts for setting up a data backend in the company, up to a complete solution for data management based on the PLM system Contact Elements. Depending on the chosen solution approach, the collected data and/or analysis results are available for further. The requirements for role and data access management vary greatly depending on the intended use cases. Particularly with regard to collaboration across company boundaries, there is a great need to be able to control access to released data of one’s own company in a fine-grained manner. The Contact platform with its mature rights management capabilities is used in the project, and the careful assignment of rights in the respective target platforms is used for data from the source systems in order to guarantee maximum security and transparency for the companies involved. Beyond the use cases in the project, concepts are being developed for anonymizing and filtering data releases. In addition, time-bound releases between companies will be considered, enabling, for example, a “subscription model” for usage data.
A wide range of different scenarios were highlighted in the project’s use cases, which is why a “one-size-fits-all” solution for the data backend does not seem realistic. Instead, the modular reference toolkit of the AKKORD project provides the range of solution modules presented here in order to be able to address the individual requirements of companies.
Author and Contact Person: