Arbeitsbericht aus dem Leistungsbereich „Daten-Backend-System“ – Der Datenzugriff
Im Leistungsbereich „Daten-Backend-System“ werden Bausteine für einen einheitlichen Zugriff auf Datenentwickelt. Diese werden im Projekt für den Datenzugriff zwecks anschließender Analyse eingesetzt. Die Arbeiten orientieren sich dabei an den im Projekt ermittelten Anforderungen und werden anhand der AKKORD Use Cases mit den Anwendungspartnern validiert.
Ausgangssituation
Eine grundlegende Voraussetzung um industrielle Datenanalysen durchzuführen, ist die Verfügbarkeit von Daten. Um neue Erkenntnisse und Wissen aus Analysen zu erschließen, werden häufig Daten aus mehreren über das Unternehmen verteilten Systemen benötigt. Die Daten müssen für die Analyse jedoch nicht nur zugänglich sein, sondern auch in passender Art und Weise aufbereitet werden. Die Anforderungen an den Zugriff sowie die Transformation bzw. die Aufbereitung hängen stark von verschiedensten Faktoren ab. Ein zentraler Aspekt, besonders aus der Perspektive des Daten-Backend-Systems, ist die im Unternehmen vorliegende Systemlandschaft. Weitere relevante Faktoren ergeben sich aus dem angestrebten Analyseziel, der geplanten Analysemethode sowie deren beabsichtigte technische Umsetzung.
Zielsetzung und Vorgehen
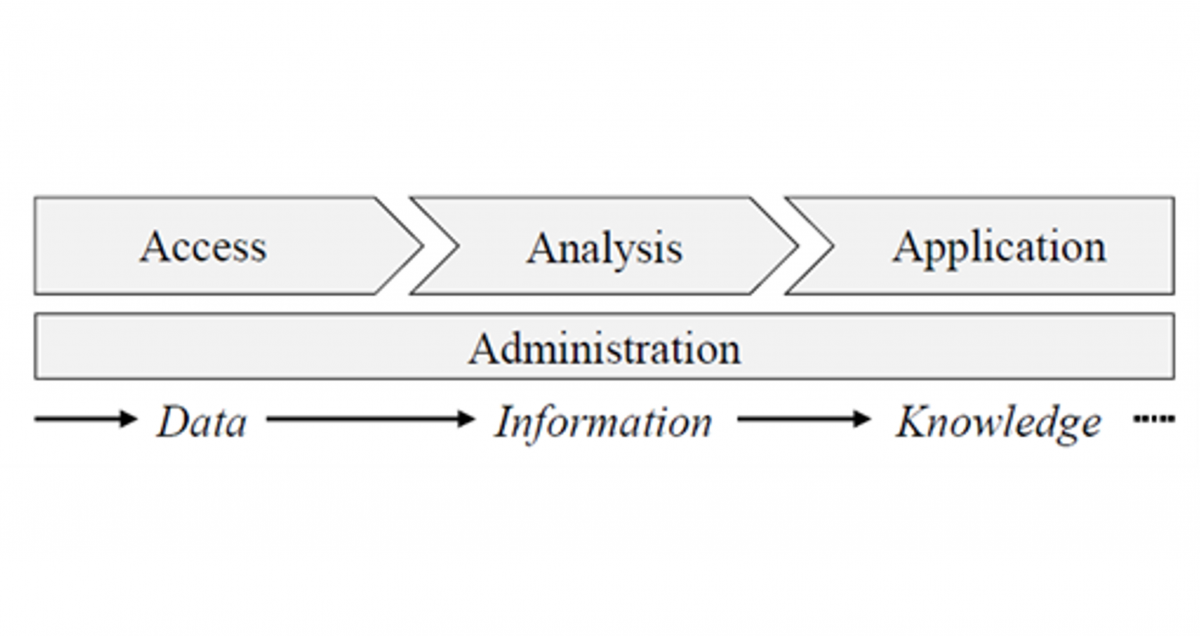
Das Ziel des 6. Arbeitspaketes ist die Entwicklung eines modularen Daten-Backend-Konzeptes, um eine individuelle Umsetzung in Abhängigkeit der gegebenen Randbedingungen für den Anwender zu realisieren. Das Daten-Backend-System ist dabei sehr eng mit den Modulen der Datenanalyse verknüpft und stellt diesen eine einheitliche Schnittstelle bereit, um den Datenzugriff zu standardisieren und Analysen so zu vereinfachen. Der Aufbau des Backend-System in einem Unternehmen kann abhängig von der bestehenden Systemlandschaft sowie dem beabsichtigten Ziel stark variieren. Idealerweise wird eine umfassende Lösung verfolgt, welche alle relevanten Daten des Unternehmens bündelt und anschließend nur mit geringem Aufwand gepflegt werden muss. Dieses Frontloading im Analyseprozess sorgt dafür, dass zukünftige Analyseprojekte mit deutlich reduziertem Gesamtaufwand realisierbar sind.
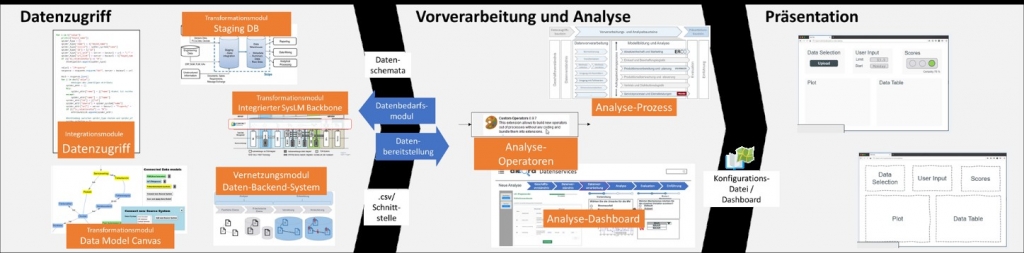
Abbildung 1: Das Backend-System im Kontext der industriellen Datenanalyse
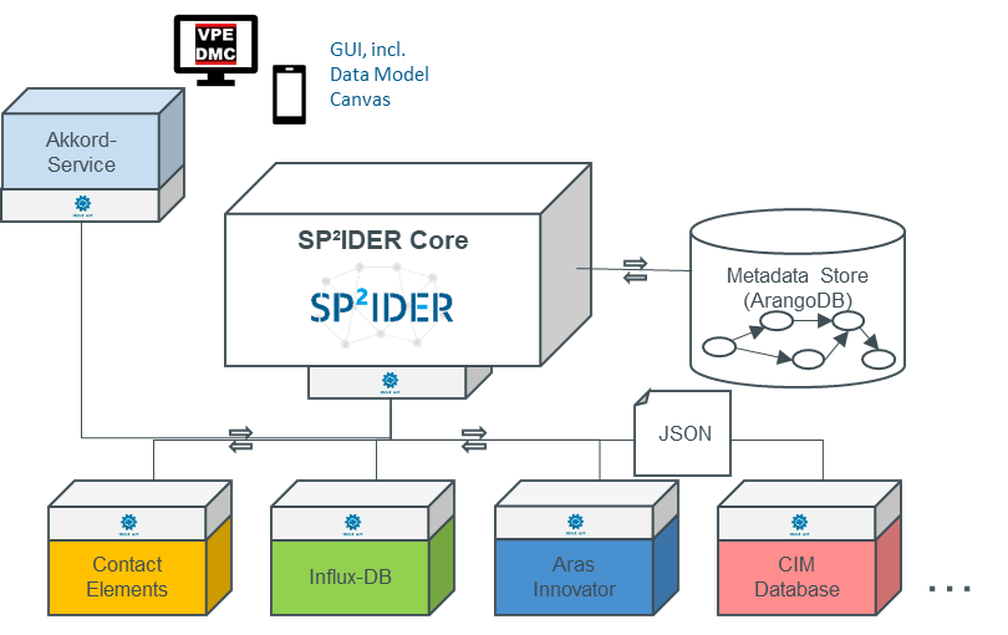
Im Rahmen der Leistungsbereichs werden unterschiedliche, modular einsetzbare Szenarien verfolgt um eine Analyse zu befähigen. Ausgangspunkt bei der Einführung eines Daten-Backend-Systems ist eine Aufnahme der IST-Situation. Dabei werden die im Unternehmen geführten Daten in einem Modell abgebildet und vermerkt, in welchem System die Daten persistiert sind.
Dieser Schritt wird durch einen Baustein des Referenzbaukasten, den Data Modell Canvas, unterstützt. Mit dem Data Model Canvas wird ein leichtgewichtiges und flexibles Tool zur Analyse und Verknüpfung von Datenmodellen bereitgestellt. Hierbei werden Datenmodelle für verschiedene Datenquellen in einer Graph-basierten Benutzeroberfläche miteinander verknüpft. Dies liefert Informationen darüber, welche benötigten Daten wo zu finden sind und welche Zusammenhänge zwischen Daten aus verschiedenen Quellen bestehen. Aus Nutzersicht steht eine intuitive Benutzeroberfläche und die Möglichkeit des Imports bestehender Vorüberlegungen (z.B. in Form von UML-Diagrammen) im Vordergrund. Bei sehr umfangreichen Systemlandschaften werden logisch zusammenhängende Teilgebiete identifiziert und zunächst getrennt betrachtet um eine Handhabbarkeit zu gewährleisten. Die definierten Teilgebiete können bei Bedarf im Anschluss verknüpft werden. Ist das Datenmodell erstellt, wird es mit den Zielen und Anforderungen der Analyse abgeglichen. Dadurch werden eventuelle Defizite im Datenbestand frühzeitig aufgedeckt und die Möglichkeit für Maßnahmen, wie das Anpassen der Analyse oder das erfassen zusätzlicher Daten, eröffnet. Sobald das Modell den Bedarf der Analyse deckt, kann es als Grundlage für den Aufbau des Backends verwendet werden. Der Referenzbaukasten umfasst verschiedene Ansätze die untereinander kompatibel sind und verschiedene IT-Strategien in Firmen unterstützen sollen.
Einordnung in den Projektkontext
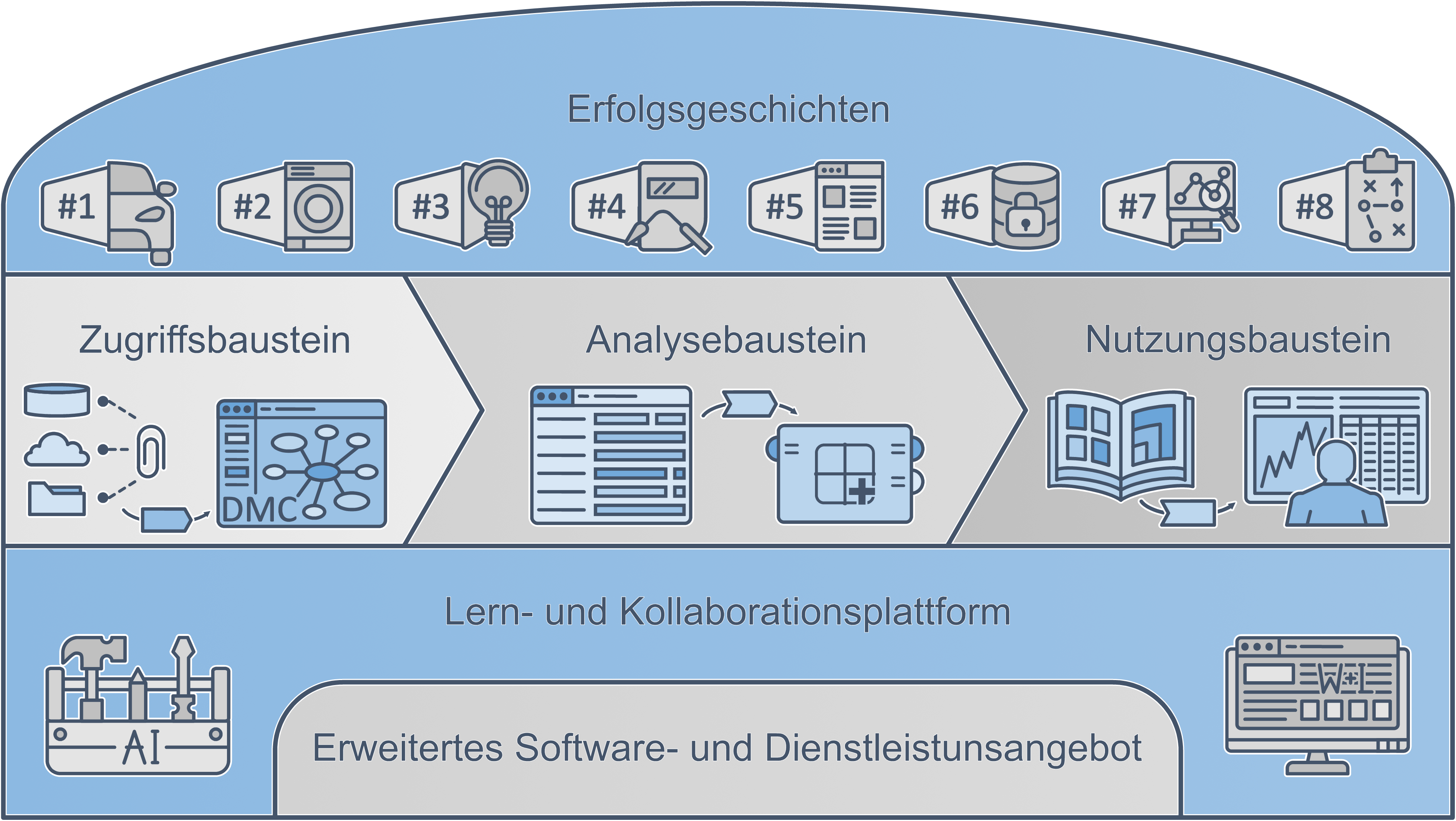
Die Abbildungen zeigen die im Projekt für das Backend entwickelten Bausteine, einmal im größeren Kontext mit der zugehörigen Datenanalyse und Präsentation der Ergebnisse und einmal fokussiert auf den Datenzugriff.
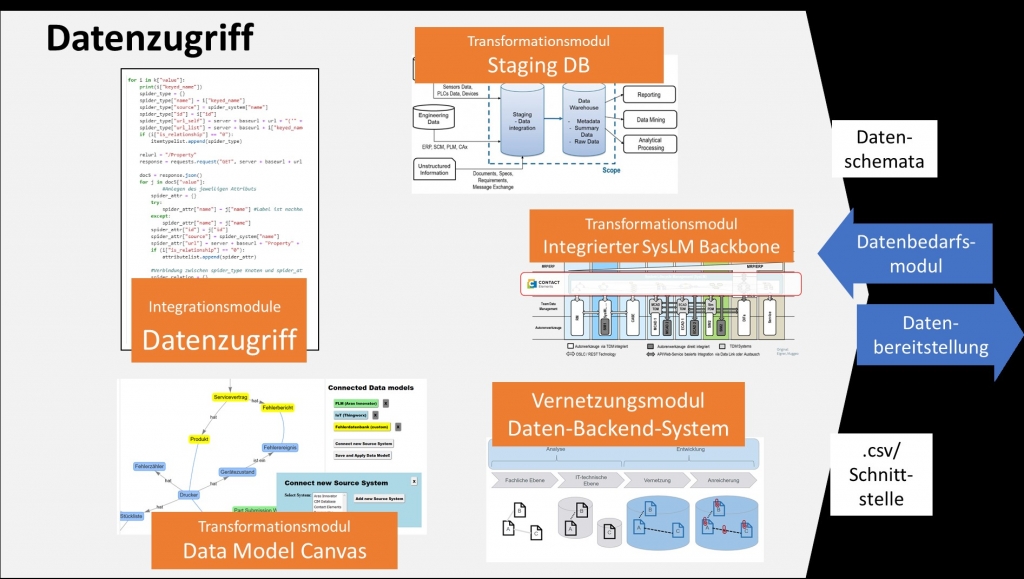
Abbildung 2: Datenzugriffsbausteine
Insgesamt ergibt sich auch im resultierenden Werkzeugkasten eine flexible, modulare Lösung, die auf die Anforderungen des jeweiligen Unternehmens anpassbar ist. So stehen neben dem vorgestellten Prozess und Tool zur Analyse vorhandener Datenmodelle Lösungen für den Aufbau einer Staging-Datenbank für Analysen in einem kontrollierten Umfeld (Projektpartner: PdTec), Konzepte für den dezentralen Zugriff auf Daten mittels Verwaltung eines gemeinsamen Metadatenmodells (Projektpartner: VPE) sowie skalierbare Konzepte für den Aufbau eines Datenbackends im Unternehmen zur Verfügung, bis hin zu einer vollständigen Lösung zur Datenverwaltung basierend auf dem PLM-System Contact Elements. Je nach gewähltem Lösungsansatz stehen die gesammelten Daten und/oder Analyseergebnisse zur weiteren Freigabe zur Verfügung. Die Anforderungen an das Rollen- und Rechte-Management variieren hierbei stark mit den anvisierten Anwendungsfällen. Besonders im Hinblick auf Kollaboration über Unternehmensgrenzen hinweg besteht ein großer Bedarf daran, den Zugriff auf freigegebene Daten des eigenen Unternehmens feingranular kontrollieren zu können. Im Projekt kommt das ausgereifte Rollenkonzept der Contact Plattform zum Einsatz. Für Daten aus den Quellsystemen wird auf die sorgfältige Vergabe von Rechten in den jeweiligen Zielplattformen gesetzt, um den beteiligten Unternehmen maximale Sicherheit und Transparenz zu garantieren. Über die Anwendungsfälle im Projekt hinaus werden Konzepte entwickelt, wie die Datenfreigaben anonymisiert und gefiltert werden können. Zudem werden zeitgebundene Freigaben zwischen Unternehmen betrachtet, was beispielsweise ein „Abo-Modell“ für Nutzungsdaten ermöglicht.
Im Rahmen der Use Cases im Projekt wurde ein breites Feld an unterschiedlichen Szenarien aufgezeigt, weshalb eine „One-Size-Fits-All“-Lösung für das Datenbackend nicht realistisch erscheint. Stattdessen wird im Rahmen des modularen Referenzbaukastens des AKKORD-Projektes die hier vorgestellte Bandbreite an Lösungsbausteinen bereitgestellt, um auf die individuellen Anforderungen von Unternehmen eingehen zu können.
Autor und Ansprechpartner: