Work report from the research area “Data-Backend-System” – The Data Model Canvas
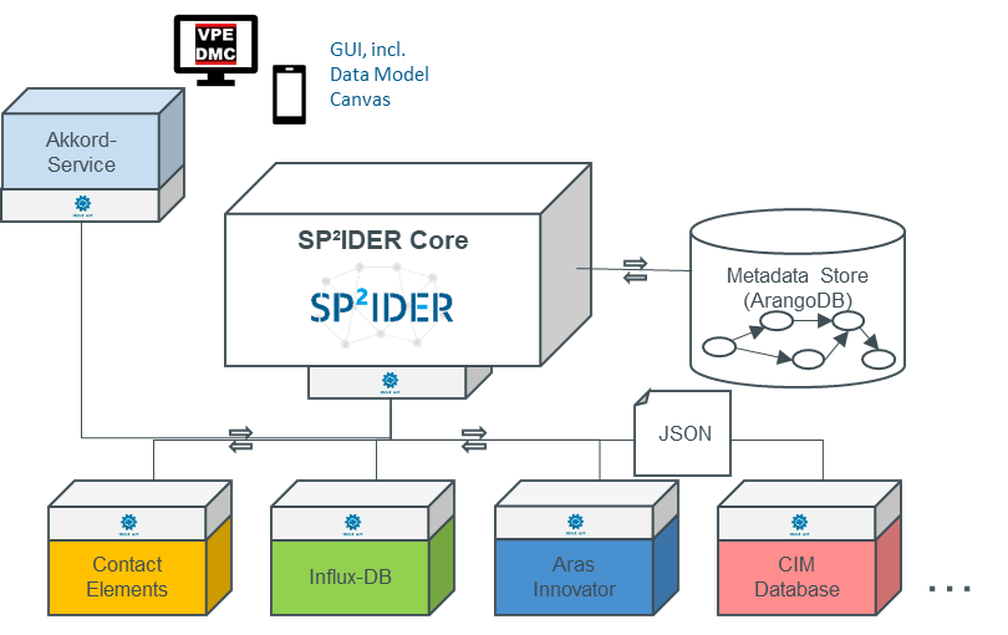
In the research area “Data-Backend-System”, modules for uniform access to data are developed. These are used in the project for data access for the purpose of subsequent analysis. The work is based on the requirements determined in the project and is validated with the application partners on the basis of the AKKORD use cases.
The Data Backend in the Context of the Project
The basic structure of the work in the research area “data backend system” is described in the previous work report. In the context of the intended block for the reference toolkit, this work is primarily located in the data access modules and thus serves as a supplier for the subsequent data preprocessing and analysis (see Figure 1).
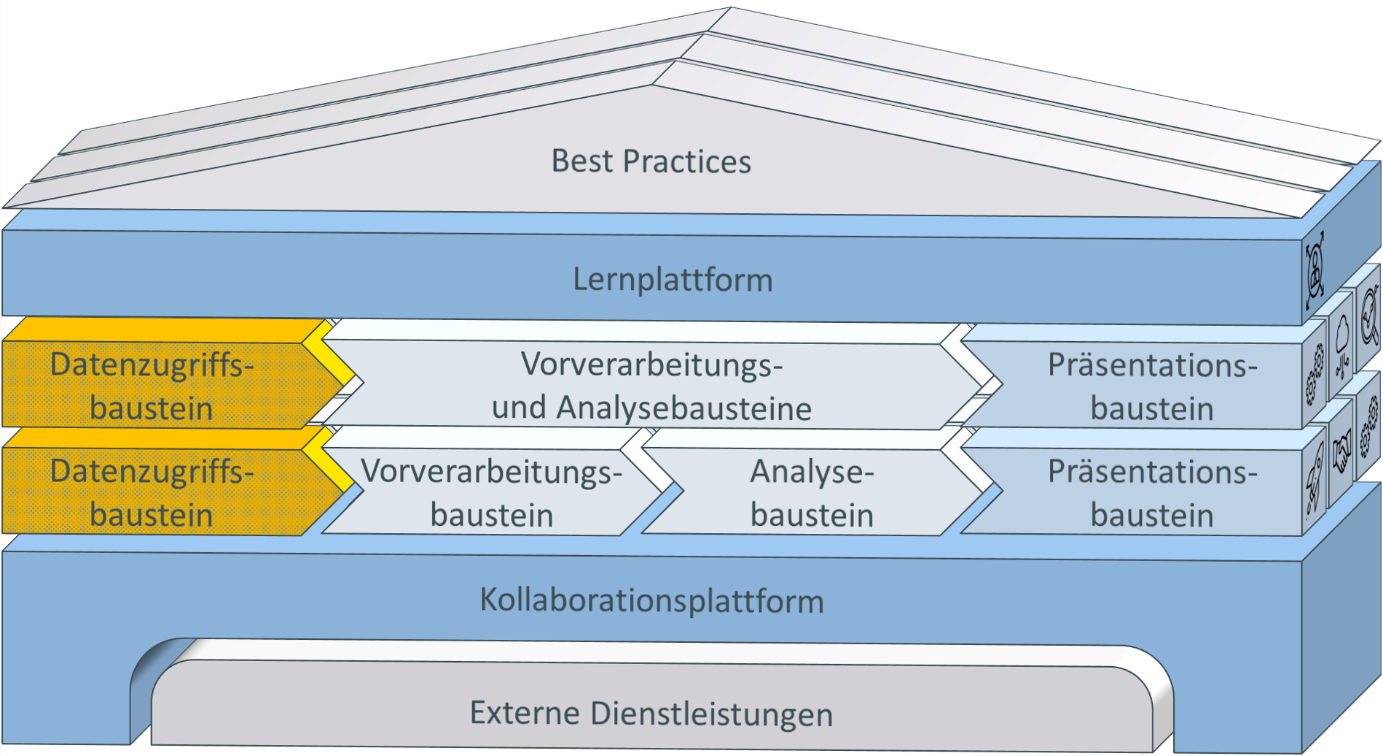
Figure 1: Placement within the reference toolkit
The modular approach taken in the research area makes it possible to address the individual requirements of a specific company. As described in the previous report, after the initial connection of a data source, the data can be prepared for transfer by means of various transformation modules. As an example, this report will take a closer look at the “Data Model Canvas” module.
The Data Model Canvas
The Data Model Canvas supports users methodically and information-technically at the construction of a technical data basis for the data analysis. The Data Model Canvas provides an implementation of the Data Understanding phase of the Cross Industry Standard Process for Data Mining (CRISP-DM), which is also pursued in other parts of the project. Based on concrete analysis scenarios, a modeling of the required data networking is performed, which in turn includes the explicitly required data sources. Data models from different sources can be analyzed and integrated into a common model for further analysis. The construction of this more domain-oriented data model will be carried out primarily by domain experts.
The prototypical implementation of the Data Model Canvas is provided as a web app and, as already described, delivers the possibility to import data models in different formats as well as already existing preliminary considerations. The data is represented in a graph with data types as nodes, which are related to each other by relations represented as edges.
The Data Model Canvas as a data access module
After importing the first data model, it is condensed to the relevant data types. The construction of the common data model then follows an iterative process (see Figure 2): Each further imported data model is also condensed to the relevant data objects. Cross-relationships between the data models are mapped by inserting new edges. Data types that represent the same facts in different systems can be merged into a common node.
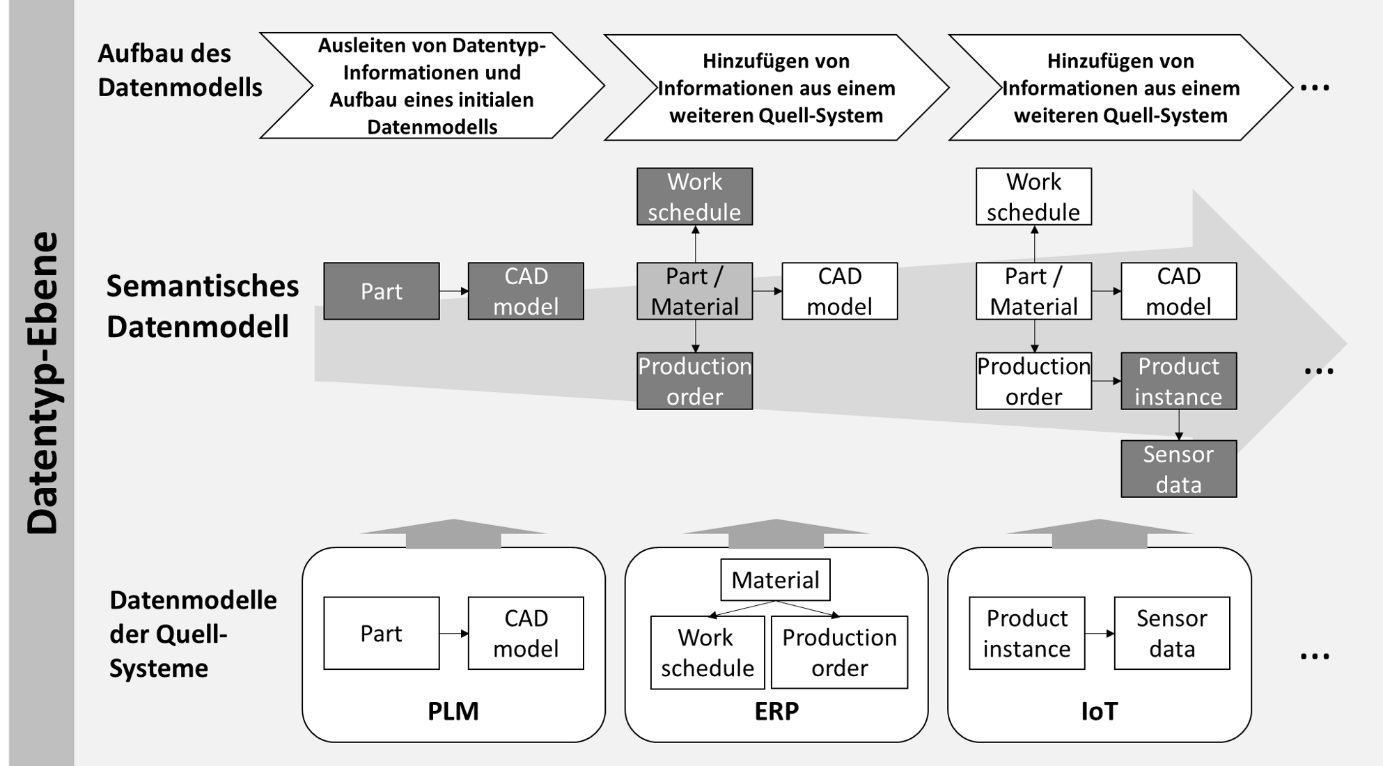
Figure 2: Interactive inclusion of new source systems
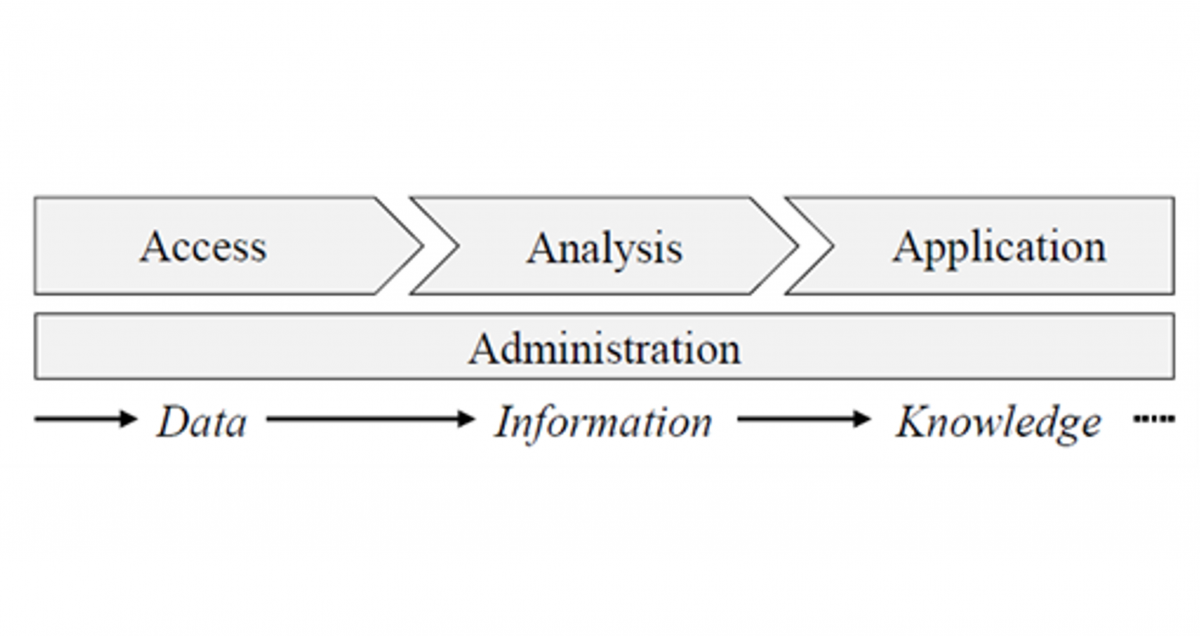
The merged information provides an initial domain-oriented understanding of the existing data, and thus maps the domain-oriented level of the data access process shown in Figure 3.
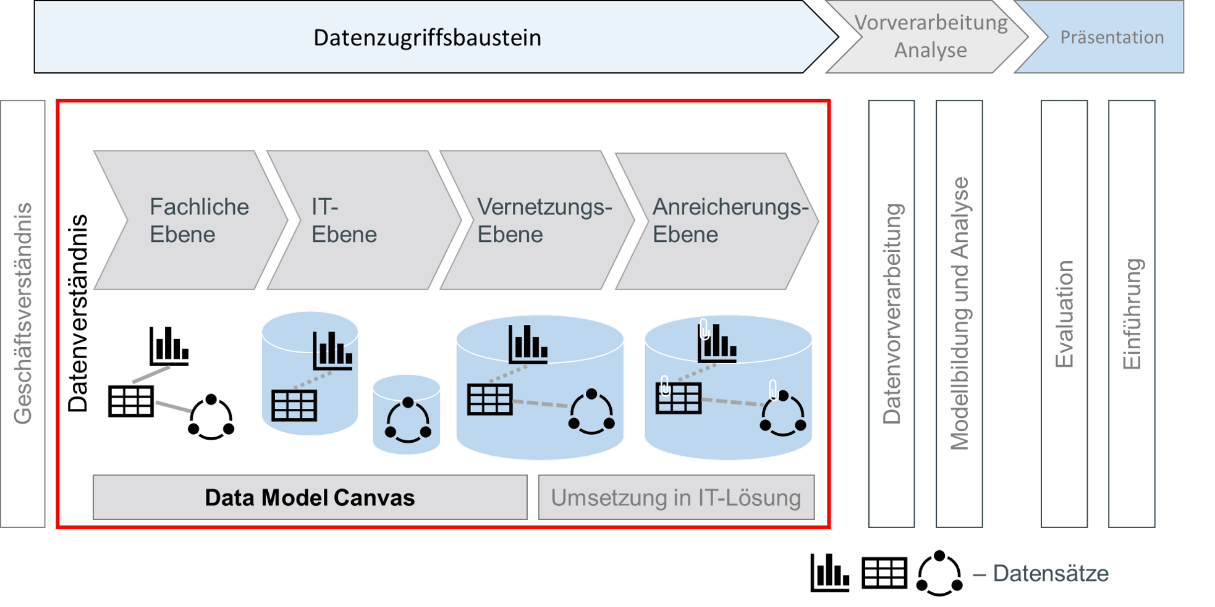
Figure 3: Process for the development of a data model for the data access modules
At the same time, the developed model also provides a technical mapping of the availability of this data in the connected source systems. The Data Model Canvas (DMC) thus enables the refinement of the developed data model to the technical level.
Once the required data as well as their relationships and storage location are known, the actual networking can take place. In this step, the models developed in the DMC are transferred to the real infrastructure so that the data is available in bundled form for analysis. Various solutions can be considered for this purpose, whereby the DMC’s structure allows great flexibility in the technical implementation. A restriction to concrete software systems to be used or a fixed structure of the final data model is avoided. In the project context, the concretely selected implementation results from the requirements of the affected use cases.
The last substep of the data access process shown in Fig. 3 is the “enrichment level”. Here, the information collected during the process is documented and made available to subsequent steps of the CRISP-DM. At this stage, a consideration of data quality and quantity should take place. First of all, it should be assessed whether the amount of data is sufficient for the intended analysis methods. In addition, suitable criteria should be used to assess what the existing data quality is. This information is then bundled and passed on to the subsequent step: Data preprocessing.
Conclusion
The Data Model Canvas offers a possible way for the integration of data models for the purpose of industrial data analysis. Following a process based on the CRISP-DM, an appropriate understanding of data can be built, refined and made usable. Within the scope of the research area, further concepts are being tested, which are expected to be highlighted in subsequent work reports. Depending on the requirements of the targeted application scenario, a suitable tool can be found.
Author and Contact Person: