Arbeitsbericht aus dem Leistungsbereich „Daten-Backend-System“ – Das Data Model Canvas
Im Leistungsbereich „Daten-Backend-System“ werden Bausteine für einen einheitlichen Zugriff auf Daten entwickelt. Diese werden im Projekt für den Datenzugriff zwecks anschließender Analyse eingesetzt. Die Arbeiten orientieren sich dabei an den im Projekt ermittelten Anforderungen und werden anhand der AKKORD Use Cases mit den Anwendungspartnern validiert.
Das Daten-Backend im Projektkontext
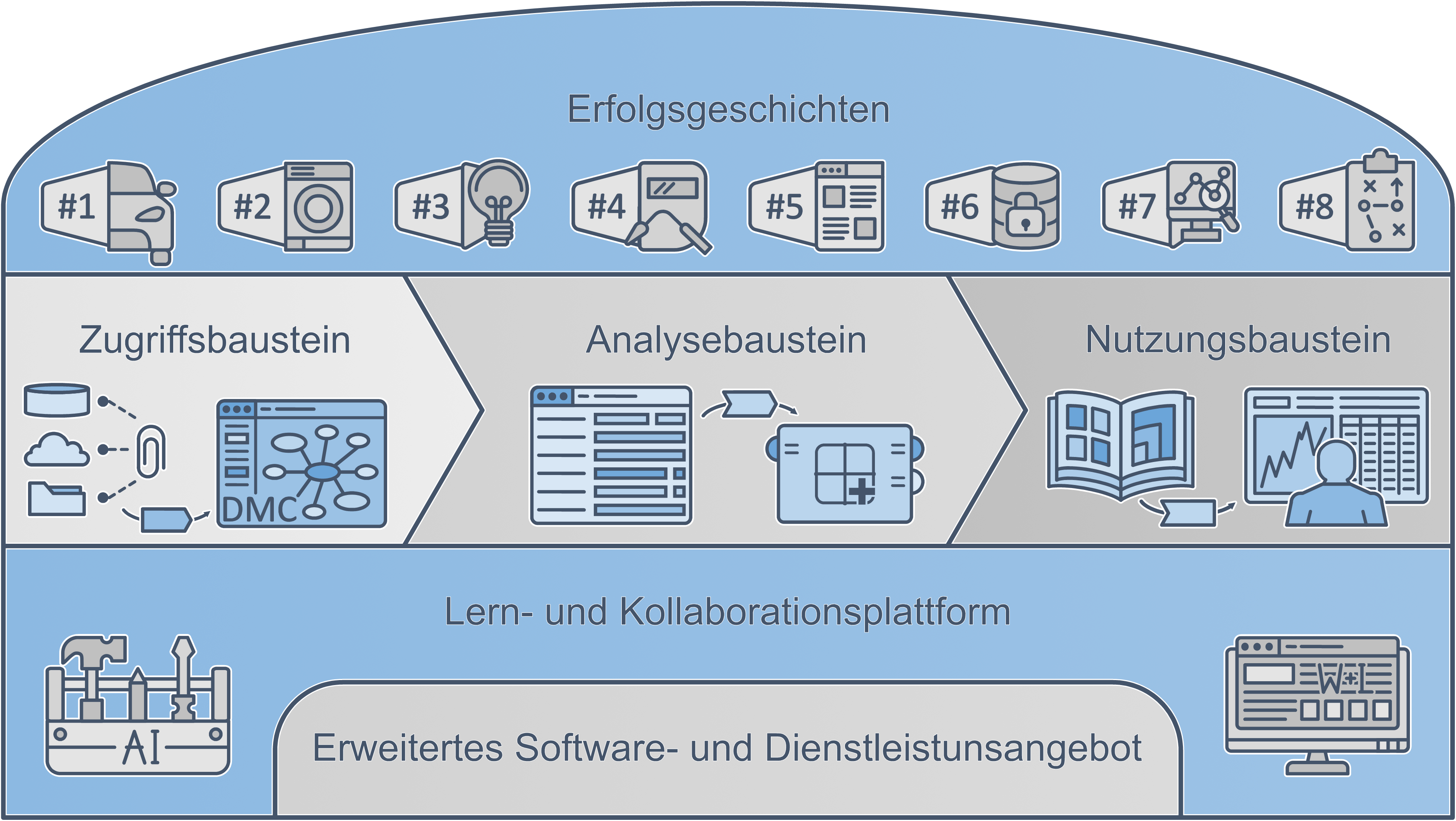
Der Grundlegende Aufbau der Arbeiten im Leistungsbereich „Daten-Backend-System“ ist im vorherigen Arbeitsbericht beschrieben. Im Kontext des angestrebten Referenzbaukastens sind diese Arbeiten vorrangig in den Datenzugriffsbausteinen verortet und dienen somit als Zulieferer für die anschließend stattfindende Datenvorverarbeitung und -Analyse (siehe Abbildung 1).
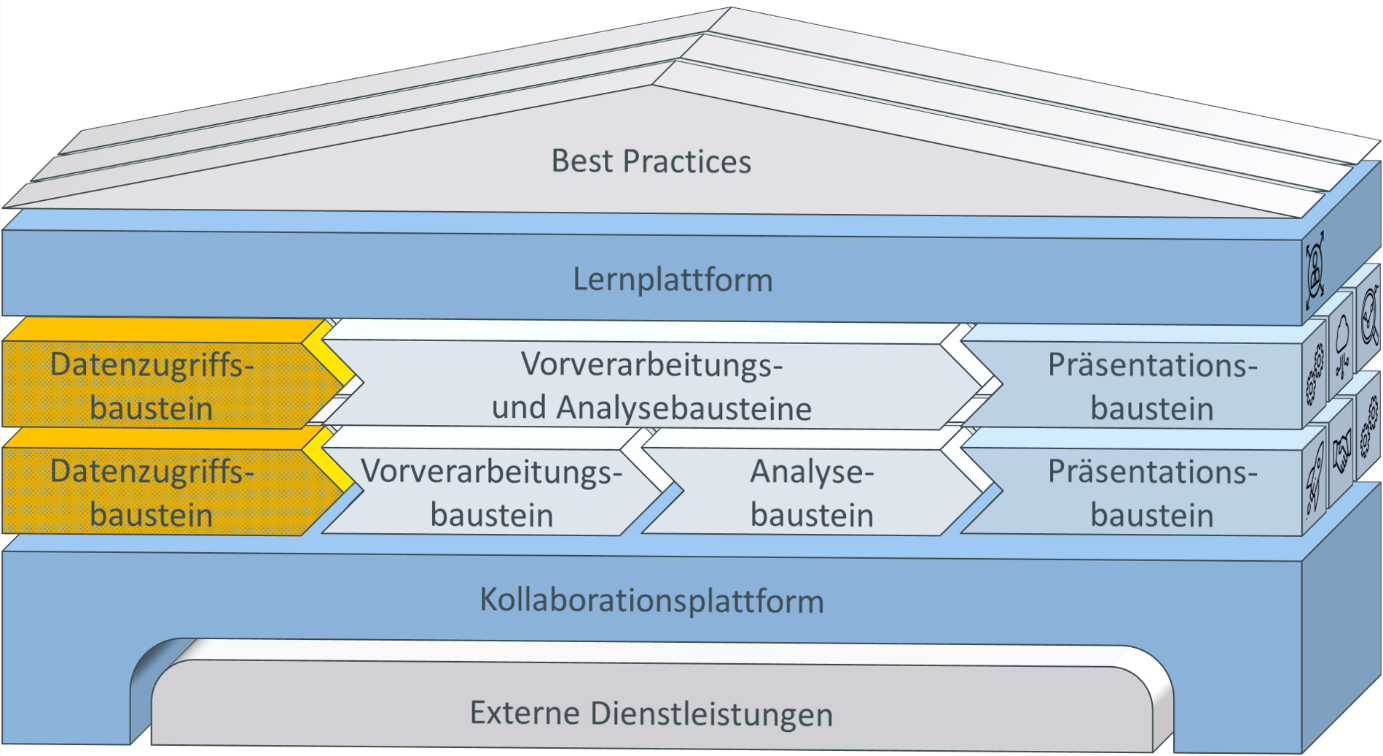
Abbildung 1: Einordnung in den Referenzbaukasten
Der im Leistungsbereich verfolgte modulare Ansatz ermöglicht es, auf die individuellen Anforderungen eines spezifischen Unternehmens einzugehen. Wie im vorherigen Bericht beschrieben, können die Daten nach dem initialen Anbinden einer Datenquelle durch verschiedene Transformationsbausteine auf die Weitergabe vorbereitet werden. Beispielhaft soll in diesem Bericht der Baustein „Data Model Canvas“ genauer beleuchtet werden.
Der Data Model Canvas
Der Data Model Canvas unterstützt Benutzer methodisch und informationstechnisch beim Aufbau einer fachlichen Datengrundlage zur Datenanalyse. Somit liefert der Data Model Canvas eine Umsetzung der Data Understanding-Phase des auch an anderen Stellen des Projektes verfolgten Cross Industry Standard Process for Data Mining (CRISP-DM). Basierend auf konkreten Analyse-Szenarien erfolgt eine Modellierung der erforderlichen Datenvernetzung, die wiederum die explizit benötigten Datenquellen umfasst. Datenmodelle aus verschiedenen Quellen können analysiert und in ein gemeinsames Modell für die weitere Analyse integriert werden. Der Aufbau dieses eher fachlich orientierten Datenmodells soll hierbei vorrangig durch Domänen-Experten erfolgen.
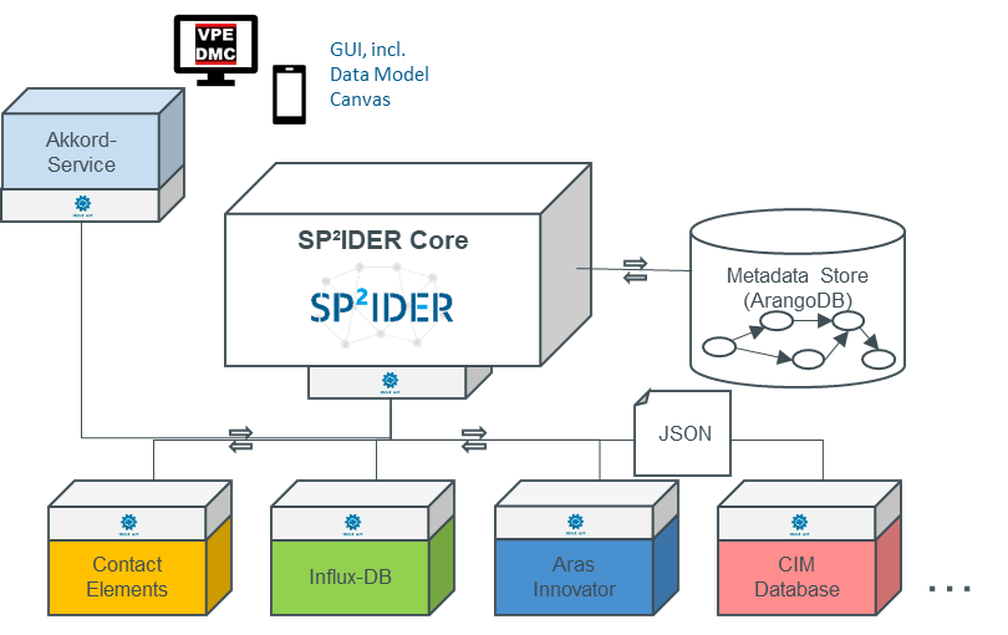
Die prototypische Implementierung des Data Model Canvas wird als Web-App bereitgestellt und liefert, wie bereits beschrieben, die Möglichkeit, Datenmodelle in verschiedenen Formaten sowie bereits bestehende Vorüberlegungen zu importieren. Die Daten werden in einem Graph mit Datentypen als Knoten, die durch als Kanten dargestellte Relation miteinander in Beziehung stehen, dargestellt.
Der Data Model Canvas als Datenzugriffsbaustein
Nach Import des ersten Datenmodells wird dieses auf die relevanten Datentypen reduziert. Der Aufbau des gemeinsamen Datenmodells folgt anschließend einem iterativen Prozess (siehe Abbildung 2): Jedes weitere importierte Datenmodell wird ebenfalls auf die relevanten Datenobjekte reduziert. Querbeziehungen zwischen den Datenmodellen werden durch das Einfügen neuer Kanten abgebildet. Datentypen, die denselben Sachverhalt in unterschiedlichen Systemen abbilden, können zu einem gemeinsamen Knoten zusammengeführt werden.
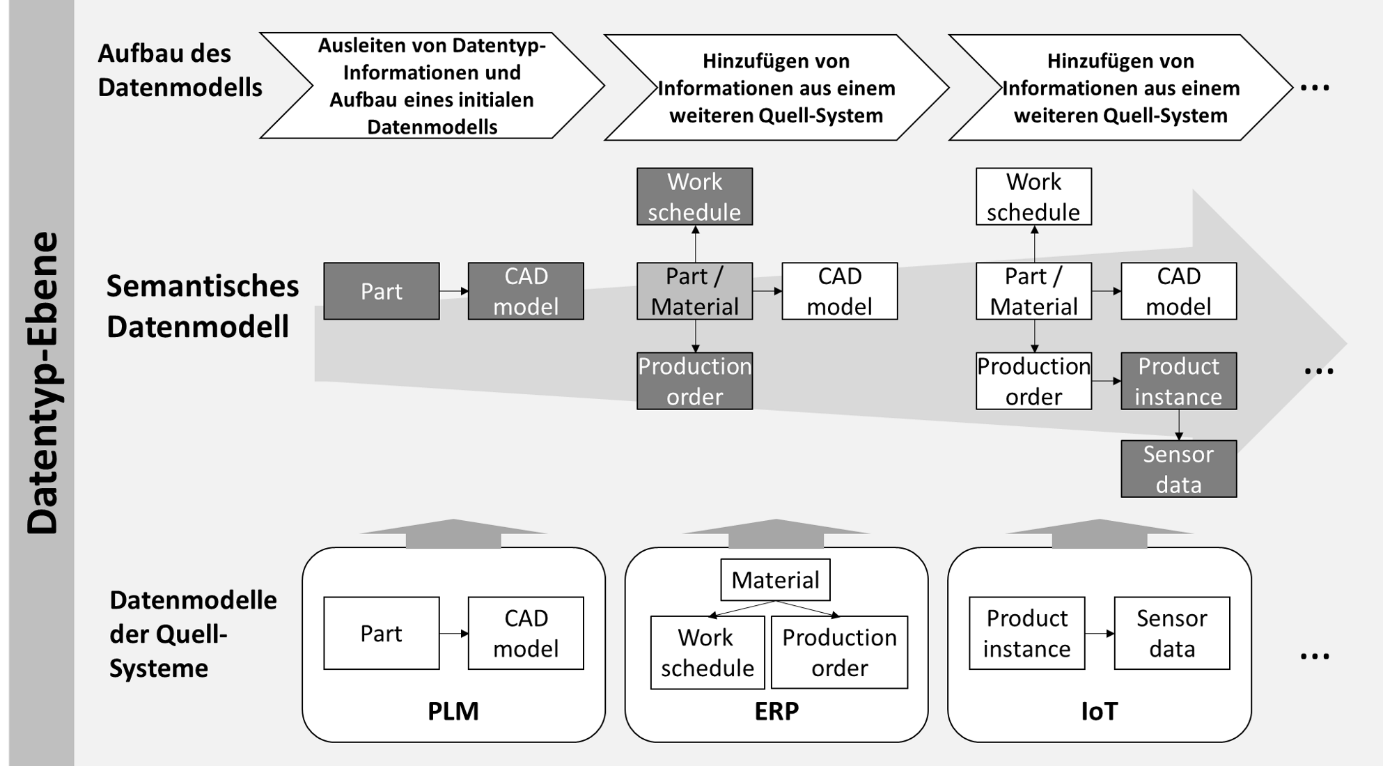
Abbildung 2: Iteratives Hinzufügen neuer Quellsysteme
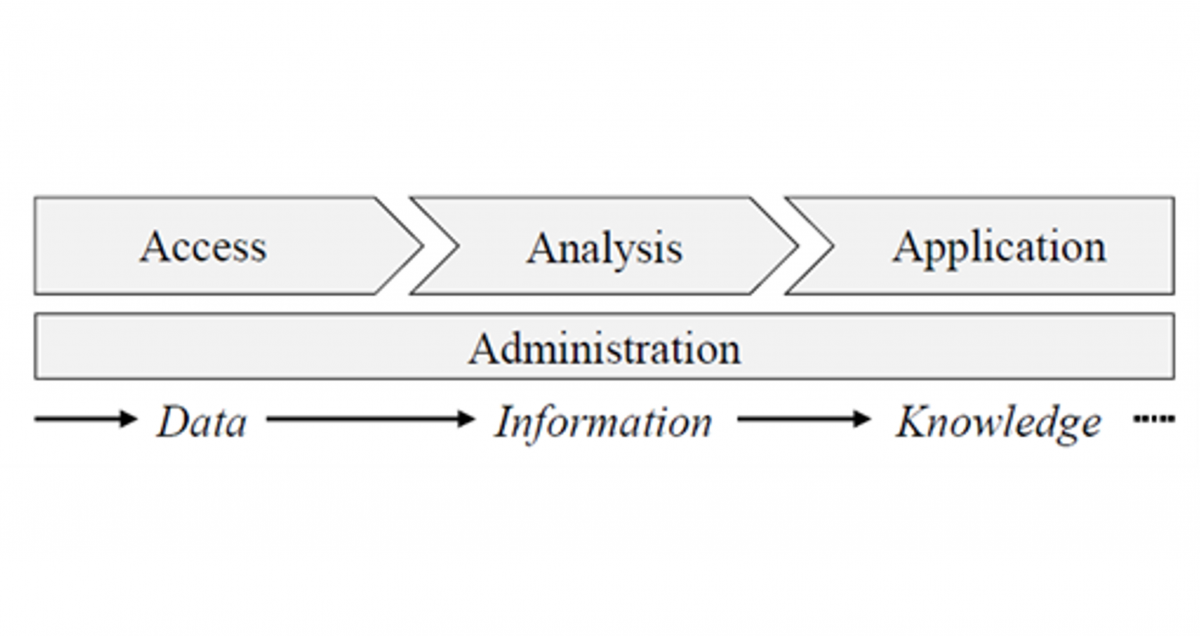
Die zusammengeführten Informationen liefern ein initiales fachliches Verständnis über die vorhandenen Daten und bilden somit die fachliche Ebene des in Abbildung 3 dargestellten Datenzugriffsprozesses ab.
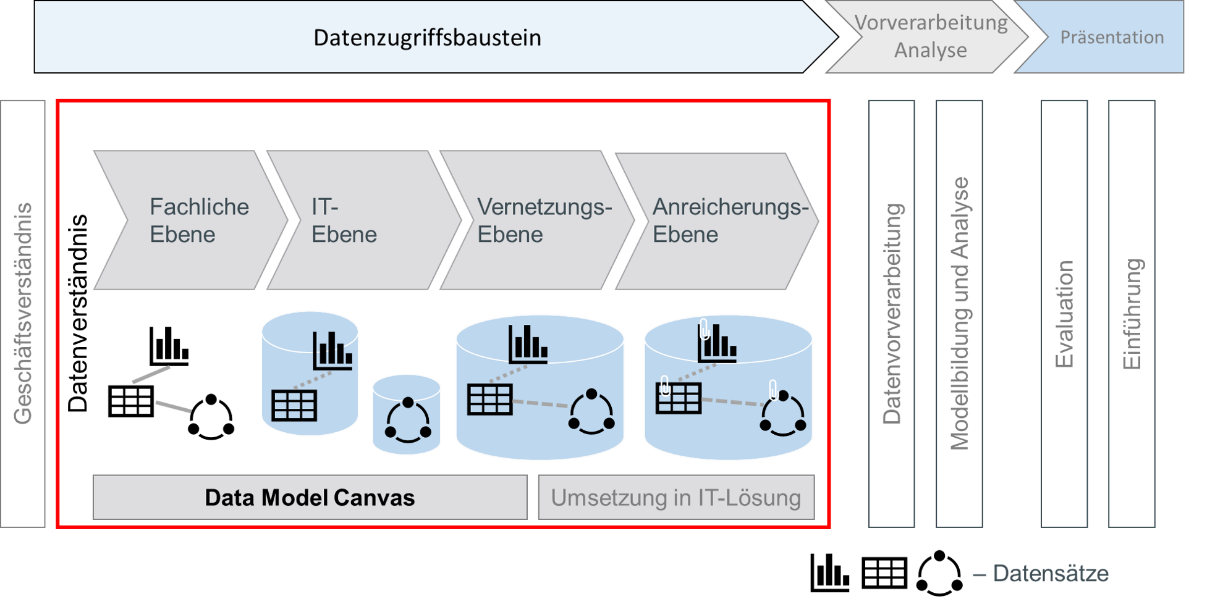
Abbildung 3: Prozess zur Entwicklung eines Datenmodells für die Datenzugriffsbausteine
Gleichzeitig liefert das entwickelte Modell eine technische Abbildung der Verfügbarkeit dieser Daten in den angebundenen Quellsystemen. Der Data Model Canvas (DMC) ermöglicht somit die Verfeinerung des entwickelten Datenmodells hin zur technischen Ebene.
Sind die benötigten Daten sowie ihre Beziehungen und ihr Speicherort bekannt, kann die eigentliche Vernetzung stattfinden. In diesem Schritt werden die im DMC entwickelten Modelle auf die reale Infrastruktur übertragen, damit die Daten in gebündelter Form für die Analyse zur Verfügung stehen. Dafür kommen verschiedene Lösungen in Frage, wobei der DMC durch seinen Aufbau eine große Flexibilität in der technischen Umsetzung erlaubt. Eine Einschränkung auf konkret zu verwendende Softwaresysteme oder eine feste Struktur des endgültigen Datenmodells wird vermieden. Im Projektkontext ergibt sich die konkret gewählte Umsetzung aus den Anforderungen der betroffenen Use Cases.
Den letzten Teilschritt des in Abb. 3 dargestellten Datenzugriffsprozesses stellt die „Anreicherungs-Ebene“ dar. Hier werden die im Laufe des Prozesses gesammelten Informationen dokumentiert und nachfolgenden Schritten des CRISP-DM zur Verfügung gestellt. In diesem Stadium sollte eine Betrachtung der Datenqualität und -quantität stattfinden. Dabei sollte zunächst abgeschätzt werden, ob die Datenmenge für die angestrebten Analysemethoden ausreichend ist. Zudem sollte mit geeigneten Kriterien beurteilt werden, wie die vorliegende Datenqualität ist. Diese Informationen werden dann gebündelt dem nachfolgenden Schritt, der Datenvorverarbeitung, übergeben.
Fazit
Der Data Model Canvas bietet einen möglichen Weg für die Integration von Datenmodellen zwecks industrieller Datenanalyse. Unter Beachtung eines an den CRISP-DM angelehnten Prozesses kann ein entsprechendes Datenverständnis aufgebaut, verfeinert und nutzbar gemacht werden. Im Rahmen des Leistungsbereiches werden weitere Konzepte erprobt, die voraussichtlich in folgenden Arbeitsberichten beleuchtet werden. Je nach Anforderungen des anvisierten Anwendungsszenarios kann somit ein passendes Werkzeug gefunden werden.
Autor und Ansprechpartner: