Second Work Report: Insights into the Use Case “Comprehensive, Predictive Industrial Engineering” of Volkswagen AG
The contribution of Use Case 1 (UC1) is the development of data driven methods and tools to support holistic productivity management in Industrial Engineering (IE). To address this, existing competencies and skills are extended to facilitate the use of Industrial Data Science. UC1 focuses on the use of Industrial Data Science to design and optimize work processes. By implementing data-based decision support along the product development process and in series production, the spotlight is placed more on shaping productivity by IE.
Volkswagen AG is in charge of UC1. In this year, UC1 involves the development of a data-based decision support mainly in collaboration with RapidMiner GmbH and the Institute for Production Systems at the Technical University of Dortmund.
Using a three-step approach intends to enable data-driven decision making:
- Developing a methodology to identify similar work systems.
- Developing an automated benchmarking, which compares and evaluates similar work systems or work process design and optimization tasks.
- Developing and implementing data mining methods for the contextual provision of proposals for work process design and optimization.
The current state of UC1
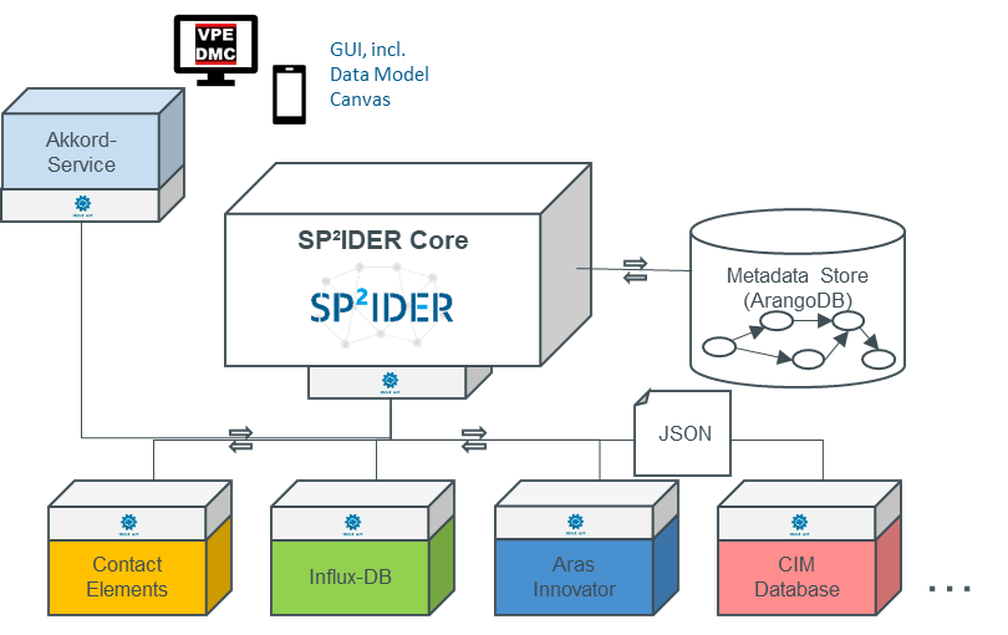
Since the beginning of the year, UC1 has continued to operationalize the similarity measure of work processes. Part-related process sequences provide the basis of the similarity measure. In order to identify part-related process sequences automatically in an assembly plan, it is quintessential to create machine-readable work processes. This is made possible by data-based identification of the categories: built-in part, position, add-on part and activities.

Figure 1: Similarity analysis categories
Built-in parts are the basis for combining operations in an assembly plan into a part-related process sequence. A part-related process sequence covers all operations in an assembly plan that can be assigned to a specific built-in part. However, the same part may represent the built-in part in one process step and the add-on part in another process step, so that differentiation is necessary. With regard to the position, a distinction can be made between process sequences that are carried out at different installation positions on the vehicle (e.g. installation process of the left and right exterior mirror). The activities include the performed work steps within a part-related processes sequence and enable comparisons of individual work steps.

Figure 2: Representation of the text mining process
Due to the volume of data, an “autoFill” feature is essential to the success and rollout of a data‑driven decision support tool. However, this requires extensive data preprocessing. The textual descriptions of the work operations contain most of the information needed to “autoFill” the categories. The preparation of the textual descriptions was mainly done in the last project year and is mandatory for the application of text mining methods. Users can easily extract information and patterns contained in unstructured data; the extraction by algorithms is more complex.
Extraction of relevant data is achieved by using a text processing pipeline based on the Standford CoreNLP library. The pipeline was prepared as a configurable analysis module (“NLP Tagger”). This allows a simplified usage of the NLP Tagger in the general analysis pipeline. The NLP Tagger is a part-of-speech tagger from Stanford Natural Language Processing Group (nlp.stanford.edu). Tagging assigns each word in a sentence to a syntactic category, i.e., to word types. The existing language model of the NLP Tagger has been extended to include internal master data lists. The terms contained in the lists are assigned to the word types part (built-in part, add-on part), position and activity as well as numeric IDs.
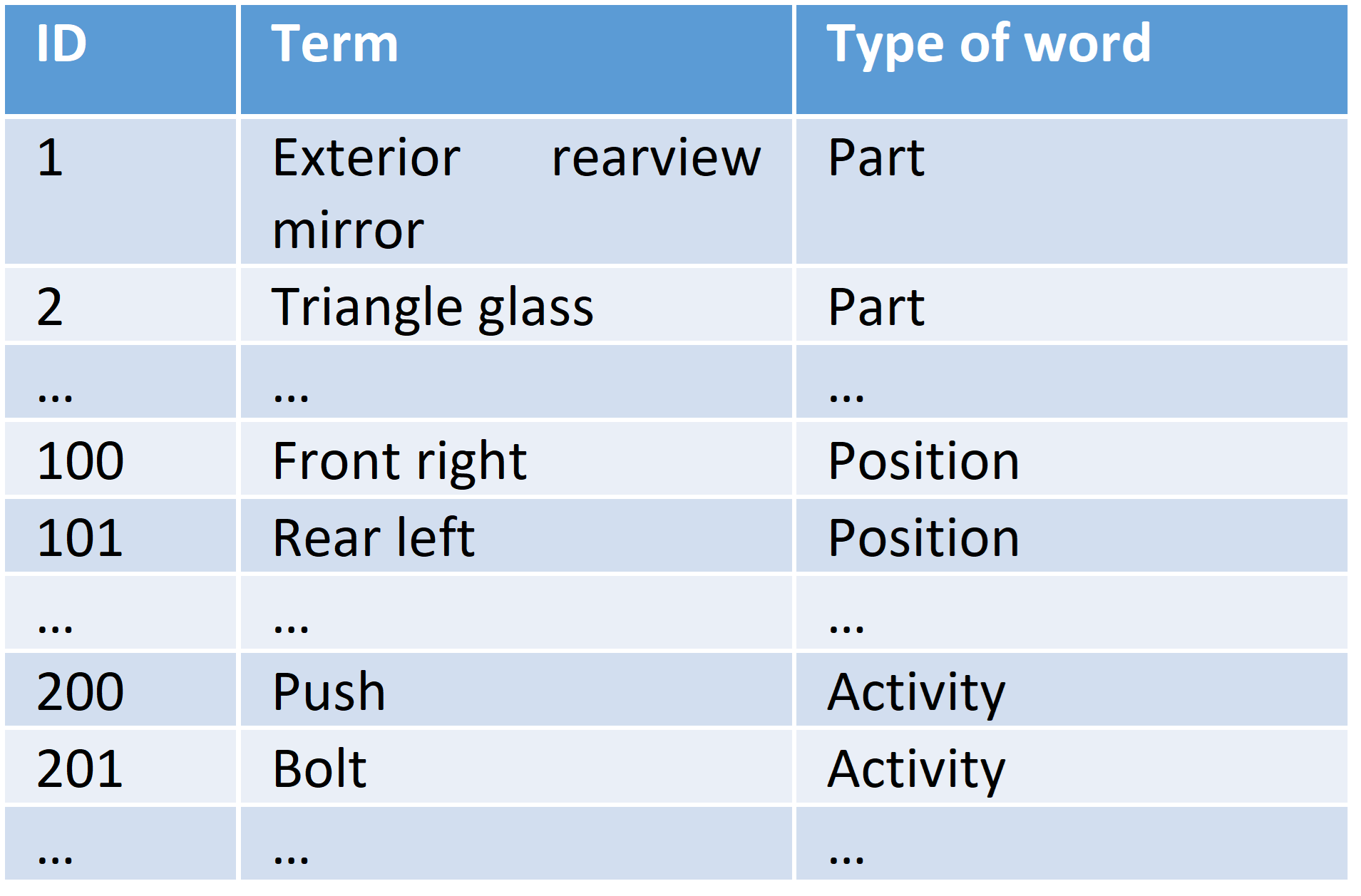
Figure 3: Structure of the master data lists
The implemented NLP Tagger enabled the first automated identification of the categories based on the work operation descriptions. This approach has already achieved good results for the word type activity. The considered master data list activity includes various synonyms of the activity terms as well as their IDs. For example, the activities “press”, “press on” and “push” are assigned to the same ID. The integration of synonyms was transferred to the part identification. Several part-related synonyms have been added to the master data list part and thus to the NLP Tagger. This resulted in a significantly better identification of parts. The differentiation between built-in and add-on parts is made via prepositions used in work operation descriptions. Prepositions are usually placed before their reference word, i.e. before the add-on part. In some cases, however, assignment to a specific built-in part is still a problem. This is due to the fact that similar synonyms for different parts occur multiple times.

Figure 4: Extract of the results of the similarity analysis
Furthermore, other data were examined in more detail and checked for their suitability for part identification. This investigation showed that part numbers are stored at operation level and are also suitable for part identification. The part numbering system can be used to identify the built-in part. However, the part numbers are not always maintained at operation level and cannot always be clearly assigned to a specific part.
In addition, neural networks were used as mechanisms to identify the four categories. The analysis pipeline includes a Long Short-Term Memory (LSTM) model and a Custom Named-Entity-Recognition (NER) model. Both approaches are based on an IE specific trained word embedding (a numerical representation of words) and allow in particular the identification of parts that are not included in the master data list.
By implementing and merging the different approaches, it was possible to automatically extract the required information from work operation descriptions. The obtained information (built-in part, position, add-on part, activity) is converted into a machine-readable format and is traced back to their generic IDs. This allows comparisons regardless of language usage and in future, of the language used in the textual descriptions. Moreover, the relevant information was aggregated at operation level. For the first time, part-related process sequences from two different plants were automatically compared.
Beyond that, the benchmarking was concretized. The focus was on the selection of relevant data, which allows the evaluation and comparison of similar process sequences (e.g., ergonomic data and time data). An initial benchmarking was implemented which considers time data. This enabled an initial benchmark of different plants and their automatically identified process sequences. To facilitate comparisons, it is further necessary to extend the relevant criteria.
Summary and outlook on further research objectives
UC1 uses a three-step approach. The similarity measure is the first step and provides the basis for the following steps. For this reason, it will be continuously developed and improved. The automated prefilling of the categories (built-in part, add-on part, position, activity) is essential to the success and rollout of a data-driven decision support tool. The focus of the next year’s project work is the operationalization of the benchmarking and the contextual provision of proposals for work process design and optimization.
Author and contact partner: