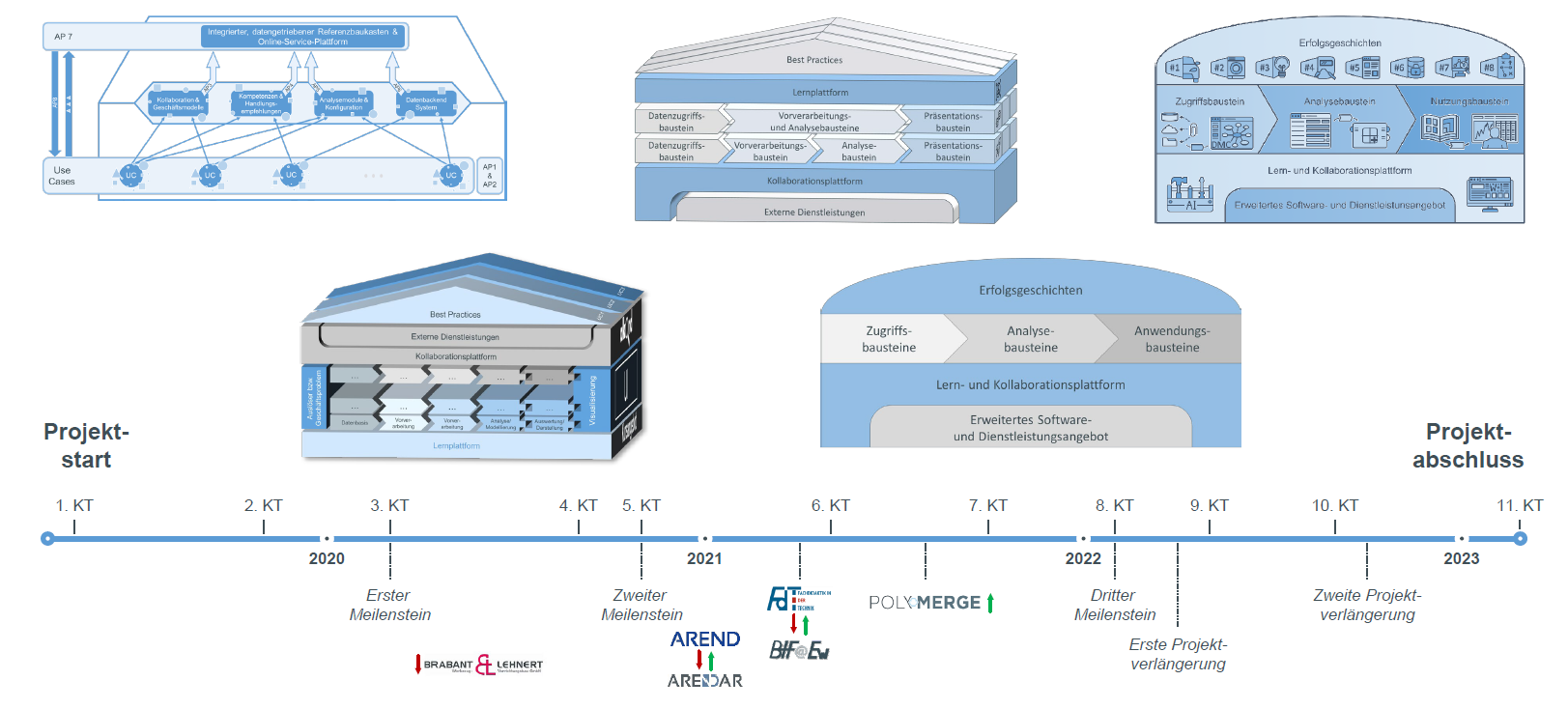
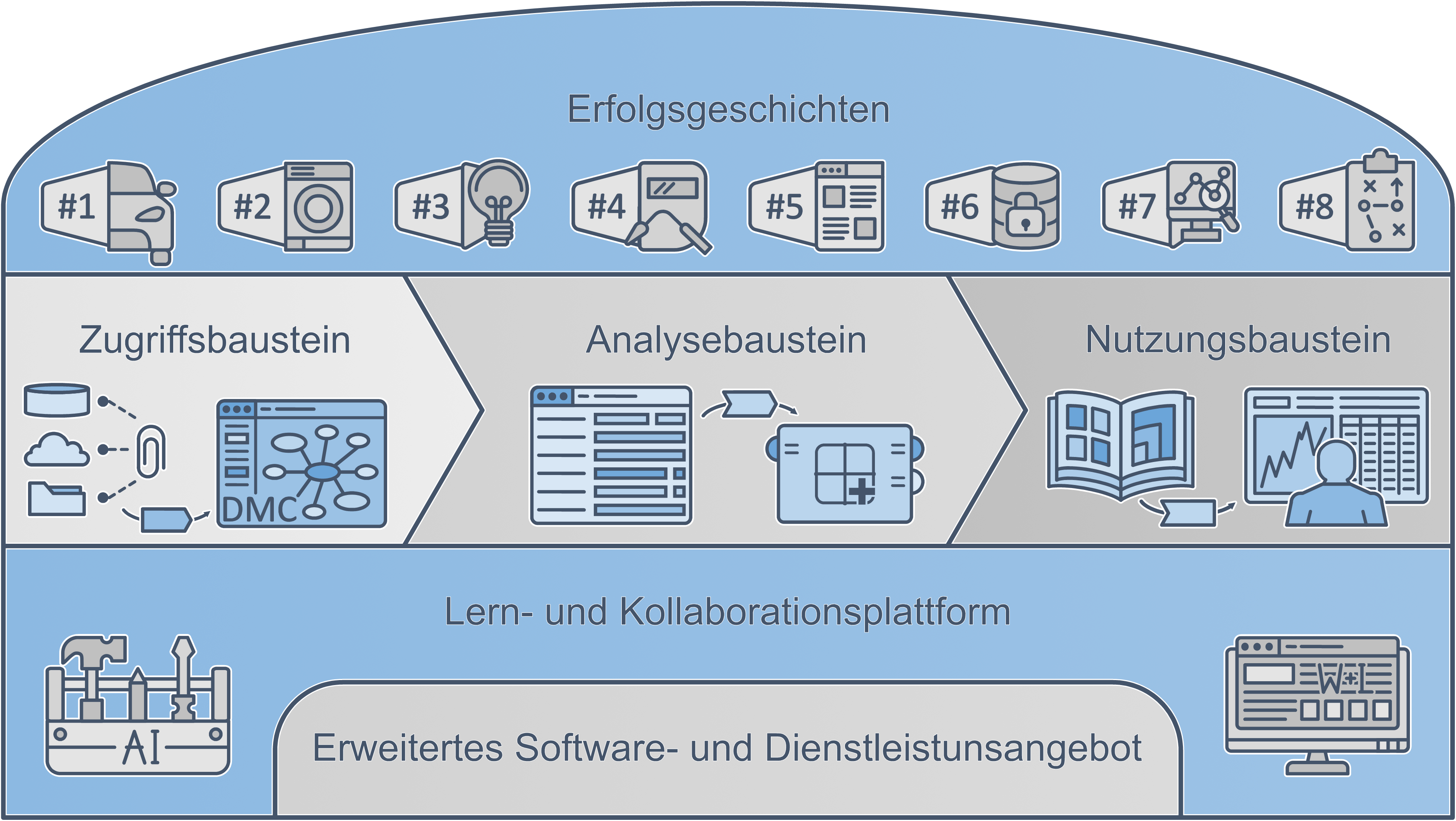
Zweiter Arbeitsbericht aus der Erfolgsgeschichte 1 „Übergreifendes, prädiktives Industrial Engineering“
Im Rahmen des Use Case 1 (UC1) werden datengetriebene Methoden und Werkzeuge entwickelt, die ein ganzheitliches Produktivitätsmanagement im Industrial Engineering (IE) unterstützen. Das Kompetenzportfolio des IE wird um Methoden und Werkzeuge des Industrial Data Science erweitert. Der UC1 fokussiert die Anwendung von industriellen Datenanalysen im Rahmen der Arbeitsprozessgestaltung und -optimierung. Durch die Implementierung von datenbasierten Entscheidungsunterstützungen entlang des Produktentstehungsprozesses und in der Serienphase wird der Fokus stärker auf die Gestaltungsaufgaben im IE gelegt.
Der UC1 wird durch die Volkswagen AG geleitet. Die Zusammenarbeit erfolgt im Rahmen des UC1 seit Beginn des Jahres schwerpunktmäßig mit der RapidMiner GmbH und dem Institut für Produktionssysteme der Technischen Universität Dortmund.
Für die Umsetzung der datenbasierten Entscheidungsunterstützung zur Arbeitsprozessgestaltung und ‑optimierung wird ein dreistufiges Vorgehensmodell verfolgt:
- Entwicklung einer Methodik zur Identifikation von gleichartigen Arbeitssystemen.
- Entwicklung eines Benchmarkings zum automatisierten Vergleich bzw. Bewertung gleichartiger Arbeitssysteme in IT-Systemen zur Arbeitsprozessgestaltung und ‑optimierung.
- Entwicklung und Implementierung von Data-Mining-Verfahren zur situativen und kontextbezogenen Bereitstellung von Vorschlägen zur Prozessgestaltung und ‑optimierung.
Stand der gemeinsamen Bearbeitung des UC1
Seit Beginn des Jahres beschäftigte sich der UC1 weiter mit der Operationalisierung des Ähnlichkeitsmaßes von Arbeitsvorgängen. Die Grundlage des Ähnlichkeitsmaßes bilden bauteilbezogene Prozesssequenzen. Zur Identifizierung dieser bauteilbezogenen Prozesssequenzen in einem Linienplan bedarf es zunächst der maschinellen Auslesbarkeit der Arbeitsvorgänge. Die maschinelle Auslesbarkeit der einzelnen Arbeitsvorgänge wird ermöglicht durch die datenbasierte Identifikation der Kategorien Einbauteil, Anbauteil, Lage und Tätigkeit.

Abbildung 1: Kategorien der Ähnlichkeitsanalyse
Eine bauteilbezogene Prozesssequenz umfasst sämtliche Prozessschritte in einem Linienplan, die einem Einbauteil zuordenbar sind. Das auf Arbeitsvorgangsebene identifizierte Einbauteil bildet damit die Basis der Aggregation der Arbeitsvorgänge zu einer bauteilbezogenen Prozesssequenz. Dasselbe Bauteil kann jedoch in einem ersten Prozessschritt das Einbauteil darstellen und in einem späteren Prozessschritt das Anbauteil, so dass eine Differenzierung erforderlich ist. Durch die Berücksichtigung des Bauraums bzw. der Lage können darüber hinaus Prozesssequenzen differenziert werden, die am Fahrzeug an verschiedenen Bauräumen durchgeführt werden (z.B. Verbauprozess des linken und des rechten Außenspiegels). Die Kategorie Tätigkeit umfasst hingegen die im Rahmen einer bauteilbezogenen Prozesssequenz durchgeführten Arbeitsschritte und ermöglicht neben einem Gesamtvergleich der Prozesskette auch einen sinnvollen Vergleich einzelner Arbeitsschritte verschiedener bauteilbezogener Prozesssequenzen.
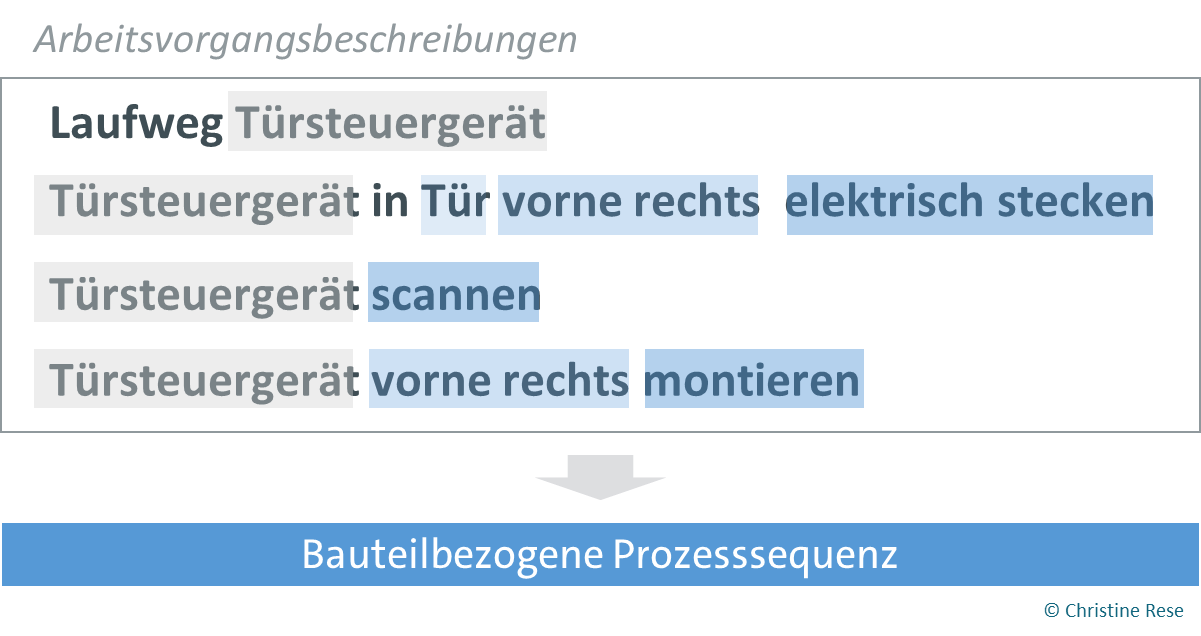
Abbildung 2: Darstellung des Text-Mining-Verfahrens
Bei großen Datenmengen ist eine automatisiert generierte Befüllung der Kategorien unerlässlich für den Erfolg und die Verbreitung eines Werkzeuges zur datenbasierten Entscheidungsunterstützung zur Arbeitsprozessgestaltung und -optimierung. Dies erfordert jedoch eine umfangreiche Datenvorverarbeitung. Der Großteil der benötigten Informationen zu den Kategorien werden über die textuellen Arbeitsvorgangsbeschreibungen abgedeckt. Die Aufbereitung der textuellen Beschreibungen erfolgte überwiegend im vergangenen Projektjahr und ist obligatorisch für eine Analyse mittels Text-Mining-Verfahren. Die in den unstrukturierten Daten enthaltenen Informationen und Muster können vom Menschen einfach extrahiert werden, die Extraktion durch Algorithmen ist weitaus komplexer.
Zunächst erfolgte die Extraktion über die Anwendung einer Textverarbeitungs-Pipeline basierend auf der Standford CoreNLP Bibliothek. Diese Pipeline wurde als konfigurierbares Analysemodul („NLP-Tagger“) für das Projekt aufbereitet, um eine vereinfachte Nutzung in der allgemeinen Analyse-Pipeline zu ermöglichen. Der NLP-Tagger ist ein Part-of-Speech-Tagger aus der Stanford Natural Language Processing Group (nlp.stanford.edu). Beim Tagging wird jedem Wort eines Satzes eine syntaktische Kategorie zugeordnet. Diese syntaktischen Kategorien sind Wortarten. Das bestehende Sprachmodell des NLP-Taggers wird kombiniert mit internen Stammdatenlisten. Die in den Listen umfassten Begriffe sind den Wortarten Bauteil (Ein-, Anbauteil), Lage und Tätigkeit zuordenbar. Den Begriffen der Stammdatenliste sind darüber hinaus auch IDs zugeordnet.
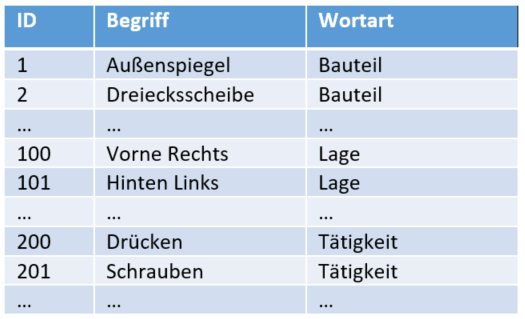
Abbildung 3: Aufbau der Stammdatenlisten
Der Einsatz des NLP-Taggers ermöglichte die erste automatisierte Identifizierung der Kategorien auf Basis der Arbeitsvorgangsbeschreibungen. Der NLP-Tagger erzielte für die Wortart Tätigkeit bereits sehr gute Ergebnisse hinsichtlich der erzeugten Tags. Die zugrunde gelegte Stammdatenliste Tätigkeit erfasst diverse Synonyme der verschiedenen Tätigkeitsbegriffe mit identischen IDs, so dass z.B. die Tätigkeiten „drücken“, „andrücken“ und „festdrücken“ derselben ID zugeordnet sind. Der dort gewählte Ansatz, der Einbindung von Synonymen in die Stammdatenliste, wurde als nächstes auf die Bauteilidentifikation übertragen. Über die Einbindung mehrerer bauteilbezogener Synonyme erfolgte eine Erweiterung der Stammdatenliste Bauteil und damit des NLP-Taggers. Durch die Einbindung von bauteilbezogenen Synonymen konnten in deutlich mehr Arbeitsvorgängen Bauteile identifiziert werden. Die Differenzierung zwischen Ein- und Anbauteil erfolgte über die in den Arbeitsvorgangsbeschreibungen verwendeten Präpositionen, die in der Regel vor ihrem Bezugswort stehen und damit ein Anbauteil charakterisieren. Die eindeutige Zuordnung zum spezifischen Einbauteil ist jedoch teilweise noch problematisch, da Mehrfachnennungen bei den Bauteilsynonymen vorkommen.
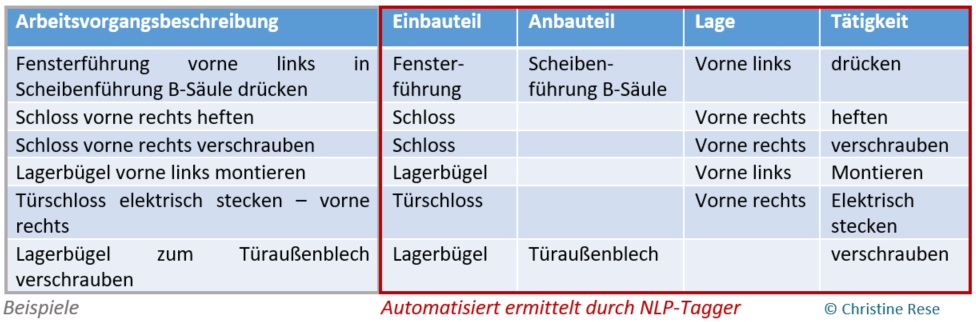
Abbildung 4: Auszug der Ergebnisse der Ähnlichkeitsanalyse
Neben den Arbeitsvorgangsbeschreibungen wurden weitere Informationen auf Arbeitsvorgangsebene näher beleuchtet und auf ihre Eignung zur Einbauteilidentifikation geprüft, so dass neben den Arbeitsvorgangsbeschreibungen auch die auf Arbeitsvorgangsebene hinterlegten Teilenummern für die Identifikation herangezogen wurden. Die Teilenummernsystematik erfasst Bestandteile, die Einbauteilen zuordenbar sind, so dass Rückschlüsse auf das Einbauteil gezogen werden können. Die Teilenummern sind jedoch nicht durchgängig auf Arbeitsvorgangsebene gepflegt und ebenfalls nicht immer eindeutig einem Einbauteil zuordenbar.
Neben dem NLP-Tagger-Ansatz und der Einbauteilidentifikation auf Basis der Teilenummernsystematik wurden für die Identifizierung der vier Kategorien auch Neuronale Netze implementiert. Es erfolgte die Implementierung eines Long Short-Term Memory (LSTM) Modells sowie eines Custom Named-Entity-Recognition (NER) Modells. Beide Ansätze basieren auf einem IE spezifischen, trainierten Word Embedding (einer numerischen Repräsentation von Worten) und ermöglichen insbesondere die Identifikation von Bauteilen, die nicht in der erweiterten Stammdatenliste enthalten sind.
Durch die Implementierung und Zusammenführung der verschiedenen Ansätze, ist es gelungen die Informationen aus den Arbeitsvorgangsbeschreibungen automatisiert zu extrahieren und somit maschinell lesbar zu machen. Die auf Arbeitsvorgangsebene automatisiert identifizierten Einbauteile, Tätigkeiten, Anbauteile und Lagen wurden ferner auf die generischen IDs der Stammdatenlisten zurückgeführt. Dies ermöglicht Vergleiche unabhängig vom Sprachgebrauch und zukünftig auch von der verwendeten Sprache. Zudem wurden sämtliche, vorliegenden Informationen auf Arbeitsvorgangsebene aggregiert und es wurden erstmals automatisiert bauteilbezogene Prozesssequenzen zweier unterschiedlicher Werke gegenübergestellt.
Neben der Operationalisierung des Ähnlichkeitsmaßes wurde das Benchmarking konkretisiert. Im Fokus stand hier die Auswahl relevanter Daten, die die Bewertung und Gegenüberstellung ähnlicher Prozesssequenzen ermöglichen (z.B. Ergonomie- und Zeitdaten). Ferner wurde ein erstes exemplarisches Benchmarking hinsichtlich der Zeitdaten implementiert. Dies ermöglichte eine erste werksübergreifende Analyse bzw. Vergleich der automatisiert identifizierten Prozesssequenzen. Weitere Vergleichskriterien sind im nächsten Schritt zu ergänzen bzw. zu definieren.
Zusammenfassung und Ausblick auf die weiteren Forschungsziele
Dem UC1 liegt ein dreistufiges Vorgehensmodell zugrunde, wobei das Ähnlichkeitsmaß die Basis des Vorgehensmodells darstellt und kontinuierlich weiterentwickelt wird. Die in den vergangenen Monaten realisierte automatisierte Befüllung der Kategorien (Einbauteil, Anbauteil, Lage, Tätigkeit) ist unerlässlich für den Erfolg und die Verbreitung eines Werkzeuges zur datenbasierten Entscheidungsunterstützung zur Arbeitsprozessgestaltung und -optimierung. Der Fokus des kommenden Projektjahres liegt auf der Operationalisierung des Benchmarkings und der Vorschlagsgenerierung.
Autor und Ansprechpartner: