Third work report from the research area “Analysis modules for networked and integrated data”
The goal in the research area “Analysis modules and configuration” is to develop and implement partial solutions of the reference toolkit for value-creating, competence-oriented collaboration in value networks. This report describes the work status of the development of a module for the customizable, automated generation of analysis dashboards.
Contextual classification of the work in the reference toolkit
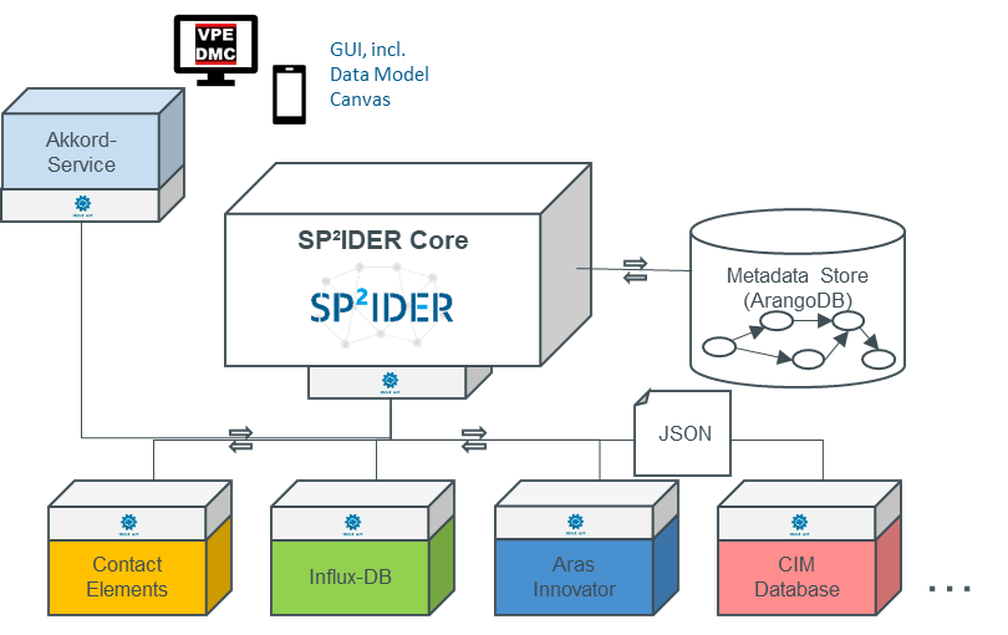
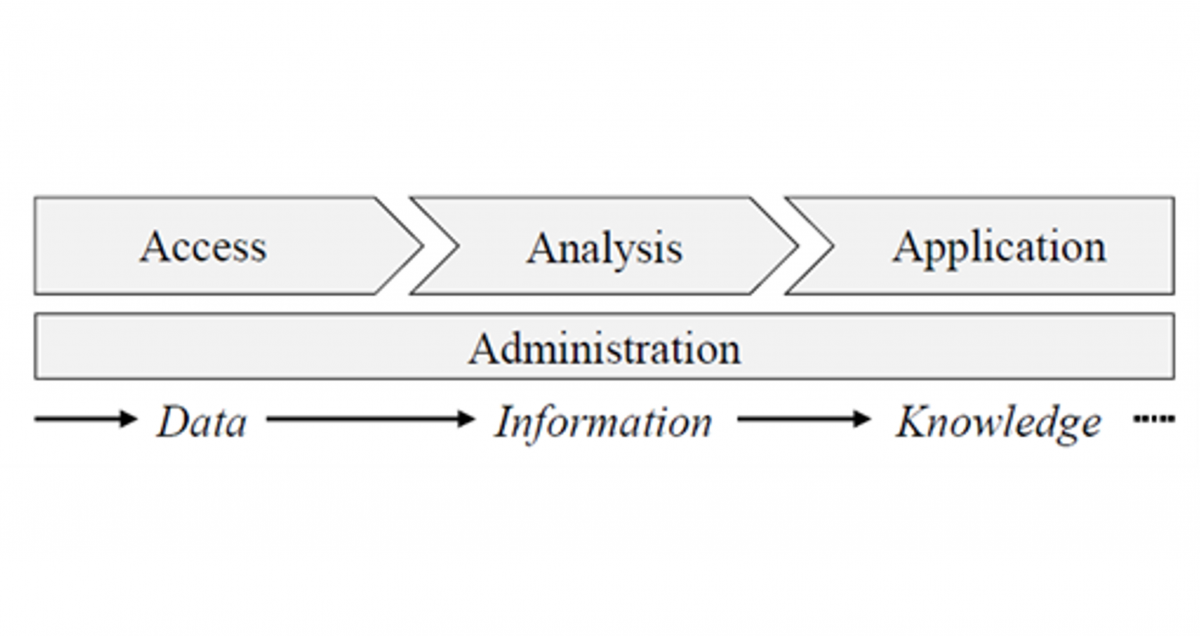
In the run-up to the third milestone meeting on 03.02.2022, the AKKORD reference toolkit (Figure 1) was finalized. A simplified and slimmed down version has emerged from the very extensive reference toolkit. The new system covers the most important modules of the AKKORD research project. The focus of the reference toolkit is still the process chain of data analysis with the access, analysis and application modules. The foundation of the modules is the learning and collaboration platform (Work & Learn – Platform). The platform is supported by the extended range of software and services offered by AKKORD partners, which users can access. The toolkit is rounded off by success stories from the use cases.
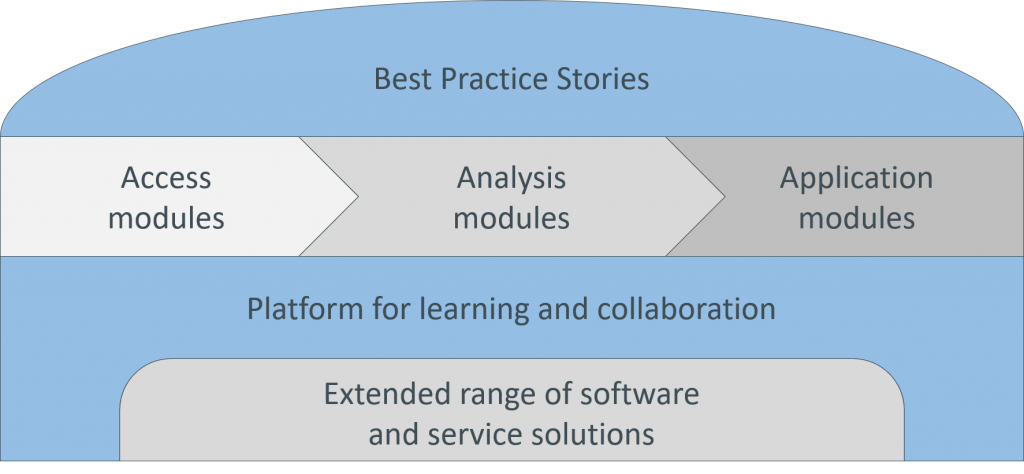
Figure 1: Finalized AKKORD reference toolkit
The present work report elaborates the results from the research area “Analysis modules for networked and integrated data”. In the AKKORD reference toolkit, the focus of the research area is in the analysis and application modules. In the following, the abstraction of one-time analyses will be discussed in more detail. Following the development of a use case in an enterprise context, it makes sense to perform an abstraction of the data processing pipeline for various reasons. Within the AKKORD research project, based on an existing concept of the project DaPro, further developments and tests of existing concepts were carried out, as well as new concepts for the simplified use of generalized analyses were developed.
As part of the work in the research area, the basic concept of generalized, reusable “problem-solving modules” (name from DaPro, Figure 2) was taken up and converted into a application concept. A few advantages shall be listed here first, before describing how exactly an abstraction can look like.
Advantages:
- Defined interfaces of the analysis provide lower integration hurdles into existing systems
- Formation of submodules reduces the complexity of a complex problem-solving process
- Decomposition of the analysis into submodules enables easier scalability
- Replacement of partial aspects by “better” modules
- Reusability of individual solutions in other projects
- More flexible design of the analysis

Figure 2: Schematic representation of possible abstracted problem-solving modules
Identification
In the context of identifying abstractable entities of a data processing pipeline, two different levels of detail of abstraction levels are applied.
- mapping of a complete analysis pipeline
Here, only the raw data of the analysis is exchanged. Both data preprocessing, cleaning, enrichment and analysis are performed in the final module.
- model creation and validation mapping
Here, the incoming data set must have gone through all preprocessing and enrichment steps. This is especially recommended for somewhat larger data sets or more extensive analysis and validation steps.
Mapping the properties of input data sets
Depending on the abstraction level of the entities from the pipeline, the input data sets are required in different quality or also in different granularities.
The requirements for these data sets are mapped by the data schema developed in the DaPro research project (Figure 2). This includes data requirements from content, to statistics, to general data descriptions. Via a graphical user interface, users are supported in mapping their own input data to the existing requirements. In this context, the AKKORD-related further developments of the data schema approach could be supplemented by additional assistance, such as an automatic conversion of value types.
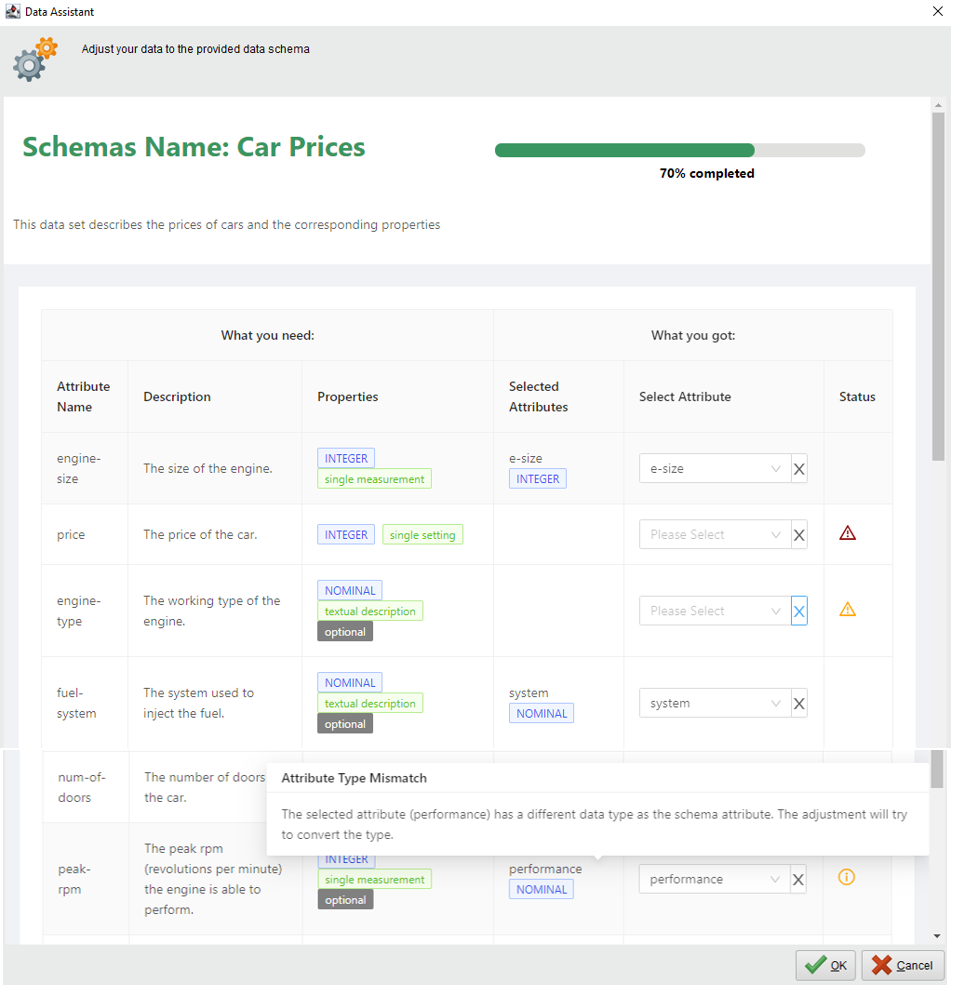
Figure 3: Assistant for adapting user data to an existing use case data schema
Abstraction process
Starting from the complete data science analysis process, the individual functionalities are considered from the point of view of generalizability and necessity. This also includes a consideration of the data required for the analysis. What is necessary – optional – redundant? In order for the analysis process to deliver the desired results, a detailed description of the attributes is recommended. In addition, certain statistical key figures (for example, distributions or number of missing values) can be specified for this purpose. The goal of the abstraction is the encapsulated process unit, which can often be modified with variables. Thereby, arbitrarily complex facts can be mapped via loops, if-else conditions and the like.
The process result is graphically visualized in RapidMiner Studio, saved as a configuration file and stored later, when the context object is created.
Results of the abstraction
The context objects, the visualization configuration, the data schema and the abstracted data processing pipeline are stored. In order for the pipeline to be recognized as a use case module, the possibility of creating a custom RapidMiner operator is used, from which a RapidMiner extension is subsequently created. These elements are finally combined in the so-called Use Case Module, which are finally used as modules in the AKKORD reference toolkit.
Further use in AKKORD context
The context objects presented above are provided automatically as part of the deployment preparation and, in addition to the data requirements in the form of the data schema, also contain more general textual information that the creator of a use case module wishes to communicate to subsequent users. The visualization identified as most appropriate by the creator is implemented by a configuration file. The third and final part of a use case module represents the abstracted analysis workflow.
These elements are combined to a so-called Use Case Module, which are finally offered as modules in the AKKORD reference toolkit (Figure 4).
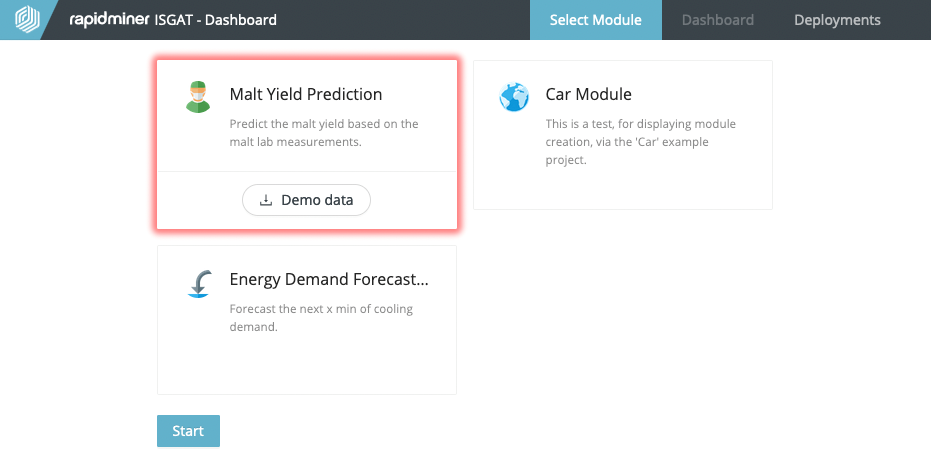
Figure 4: Use Case Modules in the AKKORD reference toolkit (Work Status)
Author and Contact Person: