Dritter Arbeitsbereich aus dem Leistungsbereich „Analysemodule für vernetze und integrierte Daten“
Das Ziel im Leistungsbereich „Analysemodule und Konfiguration“ ist die Entwicklung und Umsetzung von Teillösungen des Referenzbaukastens zur wertschaffenden, kompetenzorientierten Kollaboration in Wertschöpfungsnetzwerken. Dieser Bericht beschreibt den Arbeitsstand der Entwicklung eines Moduls zur individualisierbaren, automatisierten Erzeugung von Analyse-Dashboards.
Kontextuelle Einordnung der Arbeit im Referenzbaukasten
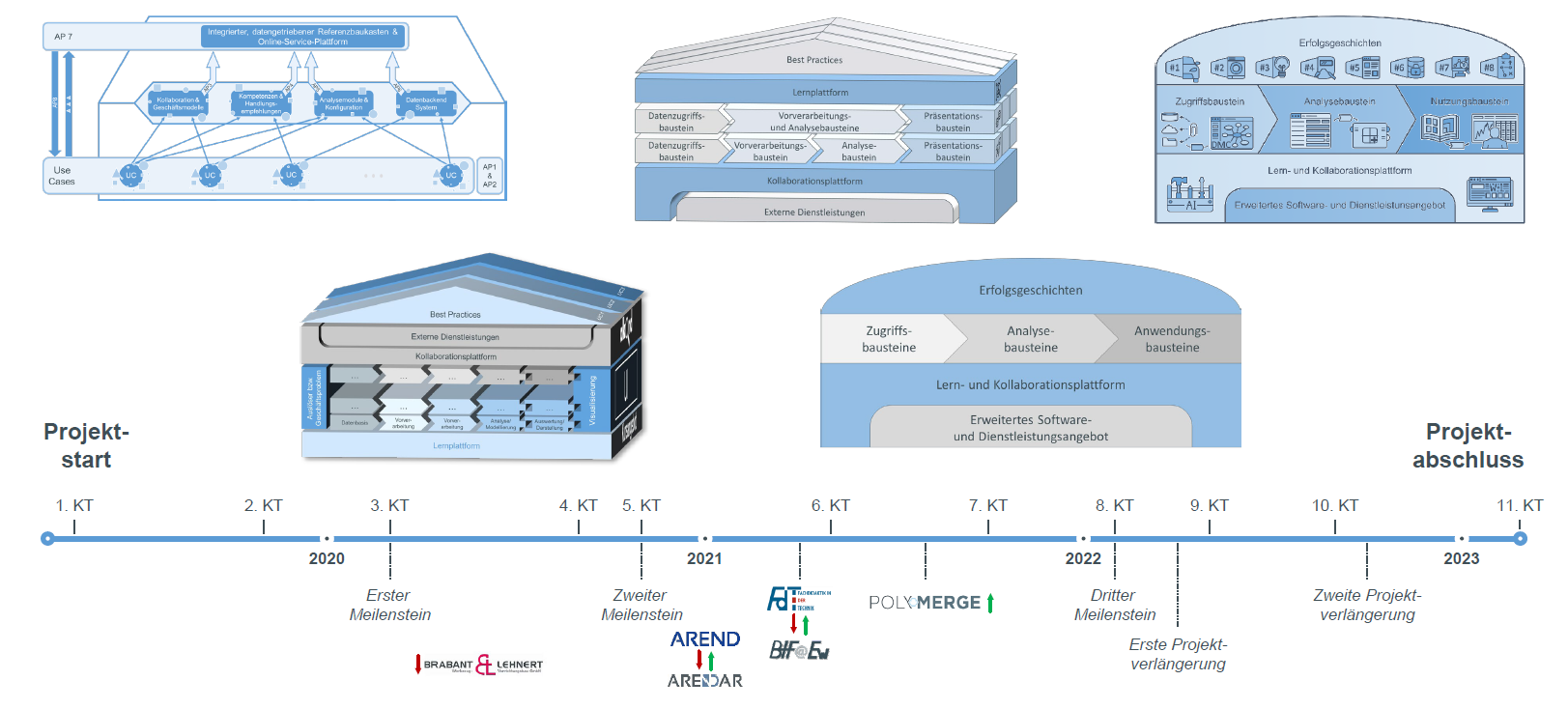
Im Vorfeld des dritten Meilensteintreffens am 03.02.2022 wurde der AKKORD-Referenzbaukasten (Abbildung 1) finalisiert. Aus dem sehr umfangreichen Baukasten ist eine vereinfachte und verschlankte Version entstanden. Das neue System deckt die wichtigsten Bausteine des AKKORD Forschungsprojekts ab. Im Mittelpunkt des Baukastens steht weiterhin die Prozesskette der Datenanalyse mit den Zugriffs-, Analyse- und Nutzungsbausteinen. Das Fundament des Baukastens bildet die Lern- und Kollaborationsplattform (Work & Learn – Plattform). Die Plattform wird unterstützt durch das erweiterte Software- und Dienstleistungsangebot der AKKORD-Partner, auf das die Nutzer zugreifen können. Abgerundet wird der Baukasten durch Erfolgsgeschichten aus den Use Cases.
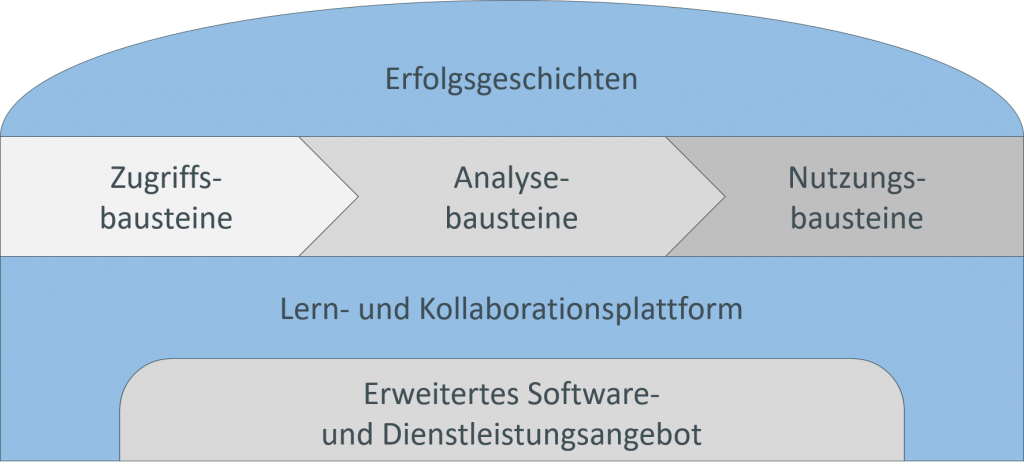
Abbildung 1: Finalisierter AKKORD-Referenzbaukasten
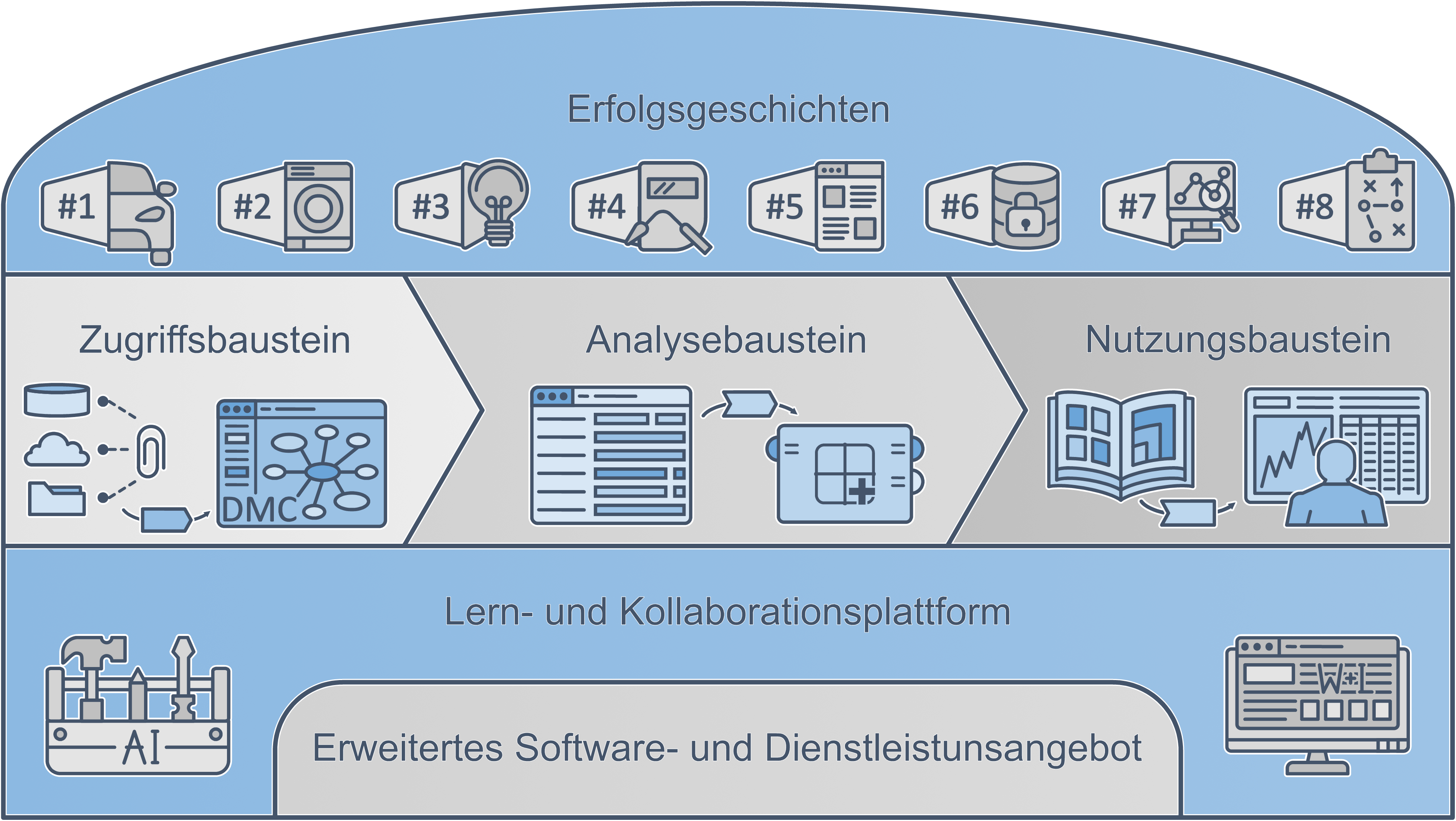
Der vorliegende Arbeitsbericht führt die Ergebnisse aus dem Leistungsbereich „Analysemodule für vernetze und integrierte Daten“ aus. Im AKKORD-Referenzbaukasten befindet sich der Schwerpunkt des Leistungsbereichs in den Analyse- und Nutzungsbausteinen. Es wird im Folgenden genauer auf die Abstrahierung von einmalig durchgeführten Analysen eingegangen. Im Anschluss an die Erschließung eines Use Cases in einem Unternehmenskontext, bietet es sich aus verschiedenen Gründen an, eine Abstrahierung der Datenverarbeitungs-Pipeline durchzuführen. Im Rahmen des AKKORD Forschungsprojekts wurde, bestehend auf einem existierenden Konzept des Projektes DaPro Weiterentwicklungen und Erprobungen bestehender Konzepte vorgenommen, sowie neue Konzepte zur vereinfachten Nutzung generalisierter Analysen entwickelt.
Im Rahmen der Arbeiten im Leistungsbereich wurde das Grundkonzept von verallgemeinerten, wiederverwendbaren „Problemlösungsmodulen“ (Name aus DaPro) aufgegriffen und in ein Nutzungskonzept überführt. Es sollen hier zunächst ein paar Vorteile aufgezählt werden, bevor beschrieben wird, wie genau eine Abstrahierung aussehen kann.
Vorteile:
- Definierte Schnittstellen der Analyse sorgen für geringere Integrationshürden in bestehende Systeme
- Teilmodulbildung reduziert die Komplexität eines komplexen Problemlösungsprozesses
- Zerlegung der Analyse in Teilmodule ermöglicht einfachere Skalierbarkeit
- Austausch von Teilaspekten durch „bessere“ Module
- Wiederverwendbarkeit einzelner Lösungen in anderen Projekten
- Flexiblere Gestaltung der Analyse

Abbildung 2: Schematische Darstellung möglicher abstrahierter Problemlösungsmodule
Identifikation
Im Rahmen der Identifikation abstrahierbarer Entitäten einer Datenverarbeitungs-Pipeline werden zwei unterschiedliche Detaillierungsgrade der Abstrahierungsebenen angewendet.
- Abbildung einer vollständigen Analyse-Pipeline
Hierbei werden nur die Rohdaten der Analyse ausgetauscht. Sowohl Datenvorverarbeitung, -bereinigung, -anreicherung als auch die Analyse werden im finalen Modul durchgeführt. - Abbildung der Modellerstellung und Validierung
Hierbei muss der eingehende Datensatz alle Vorverarbeitungs- und Anreicherungsschritte durchlaufen haben. Dies ist insbesondere bei etwas größeren Datenmengen oder umfangreicheren Analyse- und Validierungsschritten zu empfehlen.
Abbildung der Eigenschaften von Input-Datensätzen
Je nach Abstraktionslevel der Entitäten aus der Pipeline werden die Input-Datensätze in unterschiedlicher Qualität oder auch in unterschiedlichen Granularitäten benötigt. Die Anforderungen an diese Datensätze werden durch das im Forschungsprojekt DaPro entwickelten Datenschema abgebildet (Abbildung 3). Dies beinhaltet Datenanforderungen von Inhalten, über Statistiken bis hin zu allgemeinen Datenbeschreibungen. Über eine grafische Benutzeroberfläche werden die Anwender bei der Zuordnung eigener Inputdaten zu den existierenden Anforderungen unterstützt. In diesem Kontext konnten die AKKORD-bezogenen Weiterentwicklungen des Datenschema-Ansatzes um zusätzliche Hilfestellungen, wie zum Beispiel einer automatischen Konvertierung von Wertetypen, ergänzt werden.
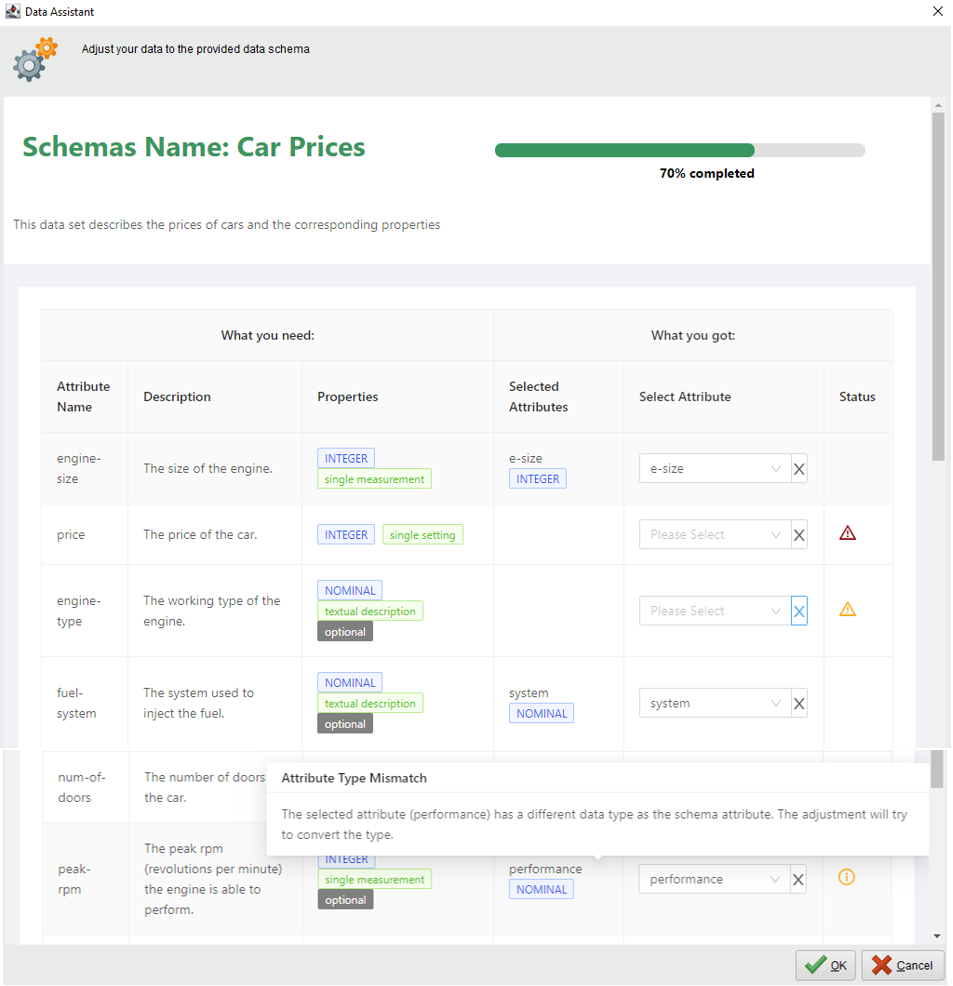
Abbildung 3: Assistent zur Anpassung von Nutzerdaten auf ein vorhandenes Use-Case-Datenschema
Ablauf der Abstrahierung
Ausgehend vom vollständigen Data-Science-Analyseprozess werden die einzelnen Funktionalitäten unter dem Aspekt der Generalisierbarkeit und Notwendigkeit betrachtet. Dazu gehört ebenfalls eine Betrachtung der für die Analyse benötigten Daten. Was ist notwendig – optional – überflüssig? Damit die Analyseprozesse die gewünschten Ergebnisse liefert, ist eine ausführliche Beschreibung der Attribute empfehlenswert. Darüber hinaus können dazu bestimmte statistische Kennzahlen (beispielsweise Verteilungen oder Anzahl von Fehlwerten) vorgegeben werden. Das Ziel der Abstrahierung ist die gekapselte Prozess-Einheit, die häufig mit Variablen modifiziert werden kann. Dabei sind beliebig komplexe Sachverhalten über Schleifen, if-else-Bedingungen und ähnliches abbildbar.
Das Prozessergebnis wird in RapidMiner Studio grafisch visualisiert, als Konfigurationsdatei abgespeichert und im späteren Verlauf, bei der Erstellung des Kontextobjekts, hinterlegt.
Ergebnisse der Abstrahierung
Die Kontextobjekte, die Visualisierungskonfiguration, das Datenschema und die abstrahierte Datenverarbeitungs-Pipeline werden gespeichert. Damit die Pipeline als Use Case Modul erkannt werden kann, wird die Möglichkeit der Erstellung eines eigenen RapidMiner Operators genutzt, aus dem im Anschluss eine RapidMiner-Erweiterung erstellt wird. Diese Elemente werden zuletzt im sogenannten Use Case Modul zusammengeführt, die schlussendlich als Bausteine im AKKORD-Baukasten eingesetzt werden.
Weiterverwendung im AKKORD-Kontext
Die oben vorgestellten Kontextobjekte werden im Rahmen der Deploymentvorbereitung automatisiert bereitgestellt und enthalten neben den Datenanforderungen in Form des Datenschemas auch allgemeinere textuelle Informationen, die der Ersteller eines Use Case Moduls den späteren Nutzern kommunizieren möchte. Die vom Ersteller als am geeignetsten identifizierte Visualisierung wird durch eine Konfigurationsdatei realisiert. Der dritte und letzte Teil eines Use Case Moduls stellt den abstrahierten Analyseworkflow dar.
Diese Elemente werden zu einem sogenannten Use Case Modul zusammengeführt, die schlussendlich als Bausteine im AKKORD-Baukasten angeboten werden (Abbildung 4).
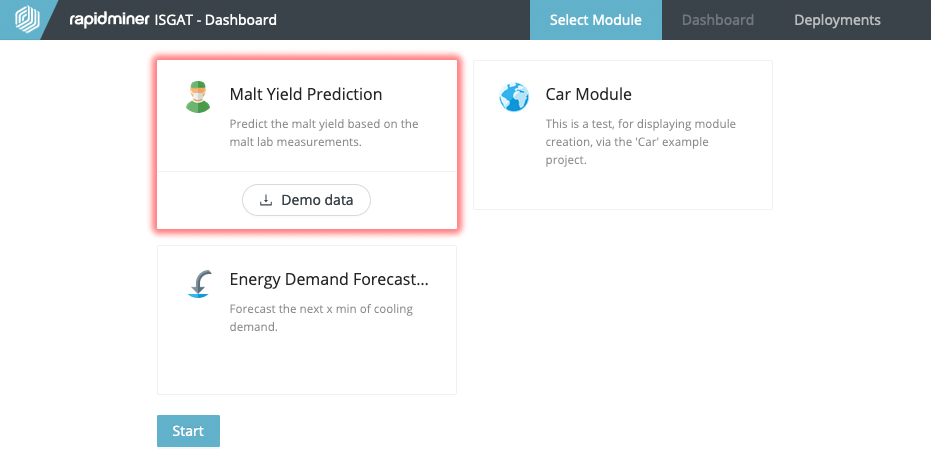
Abbildung 4: Use Case Module im AKKORD-Baukasten (Arbeitsstand)